
Introduction
Dans le domaine du machine learning, la qualité des données est primordiale. Cependant, les données réelles sont souvent désordonnées, incomplètes ou mal structurées.

Skrub est une bibliothèque Python développée pour faciliter la préparation de telles données tabulaires hétérogènes. Elle offre des outils puissants pour le nettoyage, la transformation et l’enrichissement des données, tout en s’intégrant parfaitement avec des bibliothèques populaires comme pandas et scikit-learn.
Skrub est développé par des core développeurs de scikit-learn en complément de ce package afin de faciliter l’utilisation de scikit-learn.
Alors pourquoi utiliser skrub ? Car les outils de préparation de données de scikit-learn restent limités et l’utilisation de pandas n’est pas adapté aux problématiques machine learning.
Installation de Skrub
Skrub peut être installé facilement via pip :
pip install skrub
Ou via conda :
conda install -c conda-forge skrub
Chargement d’un jeu de données réel
Pour illustrer les fonctionnalités de Skrub, utilisons le jeu de données fetch_employee_salaries fourni par la bibliothèque :
import pandas as pd
from skrub.datasets import fetch_employee_salaries
from sklearn.model_selection import train_test_split
dataset = fetch_employee_salaries()
X, y = dataset.X, dataset.y
# séparation des données en apprentissage / test
x_train, x_test, y_train, y_test = train_test_split(X,y)
Ce jeu de données contient des informations sur les employés, telles que le sexe, le département, le titre du poste, etc., ainsi que leur salaire.
Nettoyage des données avec Cleaner
Skrub propose un outil appelé Cleaner pour faciliter le nettoyage des données :
from skrub import Cleaner
cleaner = Cleaner()
X_clean = cleaner.fit_transform(X)
Le Cleaner effectue plusieurs opérations, telles que :
- La conversion des chaînes de caractères représentant des dates en objets datetime.
- La détection et la gestion des valeurs manquantes.
- La suppression des colonnes contenant trop de valeurs nulles.
On peut afficher les différentes transformations appliquées à chaque colonne du DataFrame :
cleaner.all_processing_steps_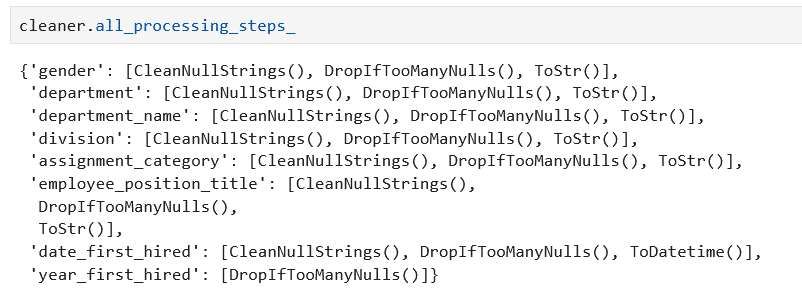
On voit ici que pour chaque colonne il applique des transformations différentes. Par exemple, un ToDatetime() pour la colonne date_first_hired.
Exploration des données avec TableReport
Pour obtenir un aperçu interactif des données, Skrub offre l’outil TableReport. La classe TableReport est un outil interactif conçu pour faciliter l’analyse exploratoire des données tabulaires. Elle génère un rapport riche et structuré, offrant une vue d’ensemble complète d’un DataFrame, ce qui permet de mieux comprendre la structure et la qualité des données avant de les utiliser dans des modèles de machine learning. Cette fonctionnalité ressemble à ydata-profiling :
from skrub import TableReport
report = TableReport(X_clean)
TableReport génère un rapport interactif affichant :
- Les statistiques descriptives de chaque colonne.
- La distribution des valeurs pour les colonnes catégorielles et numériques.
- Les associations entre les colonnes, basées sur des mesures telles que le coefficient de Cramér.
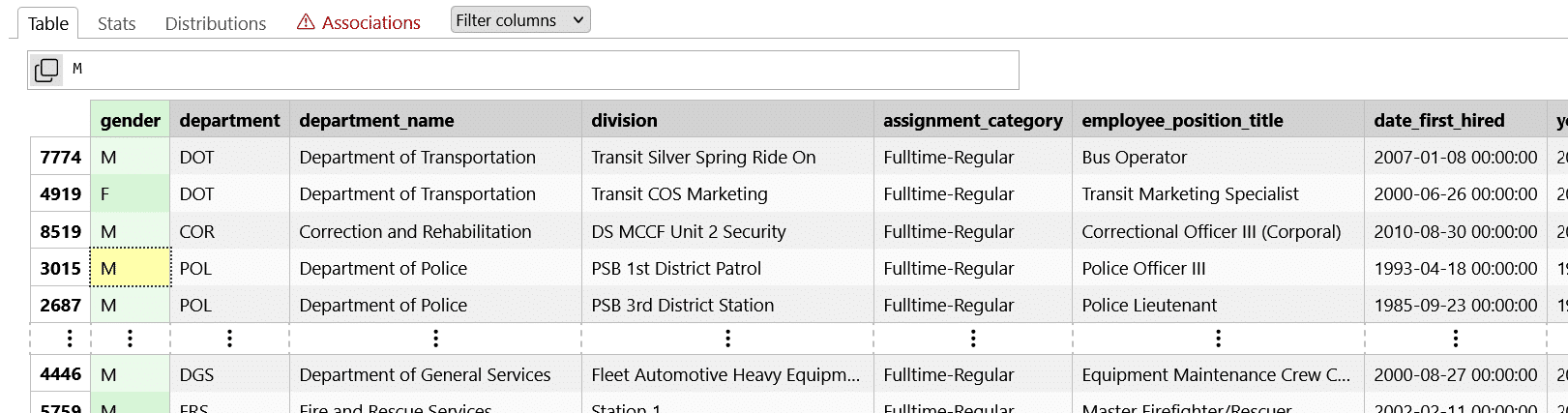
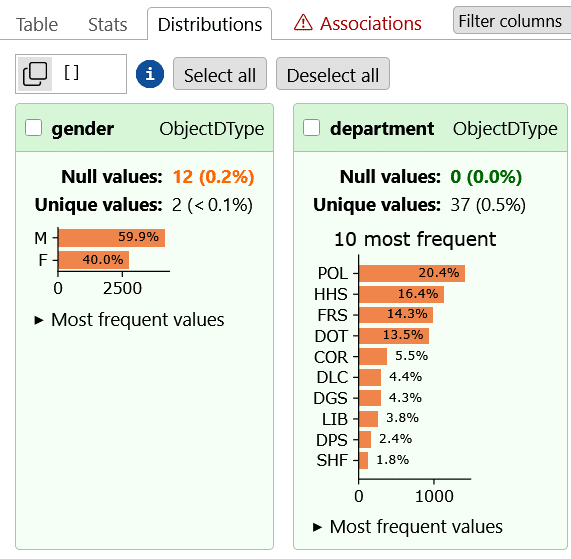
Vectorisation des données avec TableVectorizer
Pour préparer les données en vue de l’entraînement d’un modèle de machine learning, il est nécessaire de convertir les variables catégorielles en représentations numériques. Skrub propose TableVectorizer pour automatiser ce processus :
from skrub import TableVectorizer
vec = TableVectorizer()
x_train_vec = vec.fit_transform(x_train_clean)TableVectorizer détecte automatiquement les types de colonnes (numériques, catégorielles, dates) et applique les transformations appropriées, telles que l’encodage one-hot ou l’encodage de dates. Par exemple, si il découvre plus de 40 catégories sur une colonne, il n’applique pas de transformation OneHotEncoder mais il utilise un GapEncoder. Les transformations utilisées sont toutes compatibles avec scikit-learn.
Sur nos données, voici les transformations appliquées :

On voit que les colonnes numériques ne sont pas transformées et les autres colonnes sont traitées avec la transformation adaptée.
Si vous désirez appliquer une transformation spécifique à certaines colonnes (des colonnes numériques à traiter comme catégorielles par exemple), vous pouvez utiliser le paramètre specific_transformers qui vous permet d’entrer un tuple (OneHotEncoder(),['col1','col2']).
Jointure floue avec fuzzy_join
Dans de nombreux cas, il est nécessaire de fusionner des tables contenant des clés similaires mais non identiques (par exemple, des noms de pays avec des variations orthographiques). Skrub propose la fonction fuzzy_join pour effectuer des jointures approximatives (jointure à gauche) :
from skrub import fuzzy_join
left = pd.DataFrame({'Country': ['France', 'Italia', 'Georgia']})
right = pd.DataFrame({'Country Name': ['France', 'Italy', 'Germany'], 'Capital': ['Paris', 'Rome', 'Berlin']})
joined = fuzzy_join(left, right, left_on='Country', right_on='Country Name', add_match_info=True)
joinedLa fonction fuzzy_join calcule la similarité entre les chaînes de caractères et effectue la jointure même en présence de variations orthographiques. On demande ici d’ajouter une donnée sur les distances calculées. On obtient comme résultat :

Ici on voit que la fonction associe Georgia et Germany ce qui est faux, on peut modifier le niveau d’agrégation en utilisant :
joined = fuzzy_join(left, right, left_on='Country', right_on='Country Name',max_dist=0.8, add_match_info=True)
joined
Construction d’un pipeline complet
Skrub s’intègre parfaitement avec scikit-learn, permettant la construction de pipelines complets pour le traitement des données et l’entraînement de modèles :
from sklearn.pipeline import make_pipeline
from sklearn.ensemble import RandomForestRegressor
pipeline = make_pipeline(
Cleaner(),
TableVectorizer(),
RandomForestRegressor(random_state=42)
)
pipeline.fit(x_train, y_train)
Ce pipeline effectue le nettoyage des données (avec Cleaner), la vectorisation (avec TableVectorizer) et l’entraînement d’un modèle de régression, le tout de manière transparente comme vous avez l’habitude de le faire avec scikit-learn (Forêt aléatoire avec python et scikit-learn).
Le pipeline obtenu est le suivant :
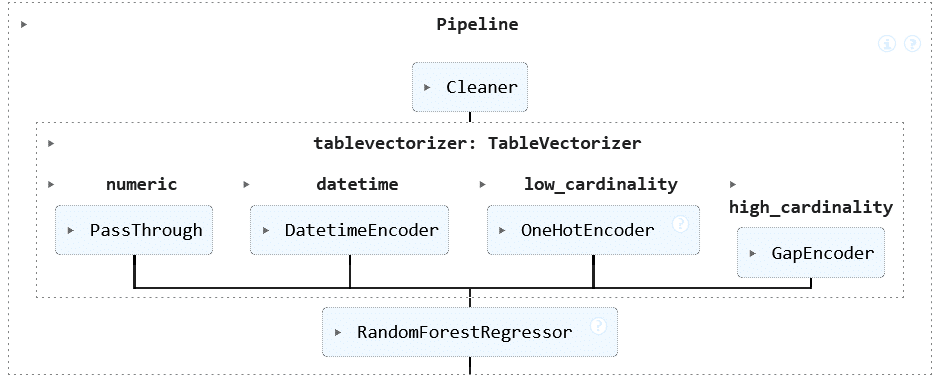
Une fois cet apprentissage effectué, il est extrêmement simple d’appliquer ce pipeline pour scorer des données de test, on pourra utiliser :
from sklearn.metrics import root_mean_squared_error
predictions = pipeline.predict(x_test)
rmsea = root_mean_squared_error(y_test,predictions)
print(f"Le RMSEA sur les données de test est de : {rmsea}")
# Le RMSEA sur les données de test est de : 6126.813024829293Le processus de machine learning est encore plus simple qu’avec scikit-learn uniquement.
Conclusion
Skrub est une bibliothèque puissante pour la préparation des données tabulaires en vue du machine learning. Elle simplifie les étapes de nettoyage, de transformation et de fusion des données, tout en s’intégrant harmonieusement avec les outils existants de l’écosystème Python. Que vous soyez data scientist, analyste ou ingénieur en machine learning, Skrub peut grandement faciliter votre travail sur des données réelles souvent désordonnées.
Ressources supplémentaires
- Documentation officielle : https://skrub-data.org/
- Dépôt GitHub : https://github.com/skrub-data/skrub
- Notebook Jupyter : Un notebook contenant tous les exemples de code présentés dans cet article est disponible ici.
- Nos formations autour du machine learning, n’hésitez pas à vous inscrire aux prochaines sessions :
- Vous voulez un accompagnement pour mettre en place vos modèles ML :
Partager cet article