
La question peut paraître simple, mais elle revient souvent en formation auprès de publics non statisticiens : comment décrire une variable qualitative, et comment croiser deux variables qualitatives ? C’est le rôle du tri à plat et du tri croisé. Voyons de quoi il s’agit, puis comment les obtenir en Python et en R, avec du code prêt à copier.
Deux statistiques descriptives simples
Le tri à plat
Imaginez une enquête où vous avez relevé la catégorie socioprofessionnelle (CSP) de vos répondants. C’est une variable qualitative. Le tri à plat consiste à présenter, dans un tableau, la répartition des répondants entre les différentes catégories. Ce sont simplement des statistiques descriptives pour une variable qualitative, que l’on représente souvent par un diagramme en bâtons.
Le tri croisé
Imaginez maintenant que vous ayez aussi relevé la ville de résidence. Le tri croisé consiste à construire un tableau qui croise les deux variables : chaque ligne correspond à une modalité de la première variable, chaque colonne à une modalité de la seconde, et chaque case compte le nombre d’individus possédant les deux caractéristiques. On peut ainsi lire d’un coup d’œil le nombre de CSP- vivant à Paris, par exemple.
Ce sont des statistiques bivariées pour deux variables qualitatives. Le tableau obtenu porte aussi les noms de tableau croisé ou tableau de contingence.
Dans toute la suite, nous travaillons sur un jeu de données comportant deux colonnes : csp et ville.
Le tri à plat avec Python
Avec Python, le package pandas fait tout le travail. Une fois les données chargées, la méthode value_counts() donne le tri à plat d’une colonne.
import pandas as pd
data = pd.read_csv("data.csv")
data["csp"].value_counts()
csp
CSP- 72
CSP+ 48
Retraité 37
Indépendant 27
Name: count, dtype: int64
Pour obtenir des proportions plutôt que des effectifs, et inclure les valeurs manquantes, on ajoute deux arguments :
data["csp"].value_counts(normalize=True, dropna=False).round(3)
csp
CSP- 0.360
CSP+ 0.240
Retraité 0.185
Indépendant 0.135
NaN 0.080
Name: proportion, dtype: float64
Le tri à plat avec R

En R, la fonction de base table() donne directement le tri à plat (elle servira aussi pour le tri croisé). La fonction summary() fait de même pour une variable de type factor, en signalant les valeurs manquantes.
data <- read.csv("data.csv")
table(data$csp)
CSP+ CSP- Indépendant Retraité
48 72 27 37
Pour aller plus loin et obtenir les pourcentages, le package questionr propose une fonction freq() très lisible :
library(questionr)
freq(data$csp)
n % val%
CSP+ 48 24.0 26.1
CSP- 72 36.0 39.1
Indépendant 27 13.5 14.7
Retraité 37 18.5 20.1
NA 16 8.0 NA
La colonne % rapporte chaque effectif au total, tandis que val% ne tient compte que des réponses valides (hors valeurs manquantes).
Le tri croisé avec Python
Avec pandas, deux approches donnent le tableau de contingence. La plus directe est pd.crosstab() :
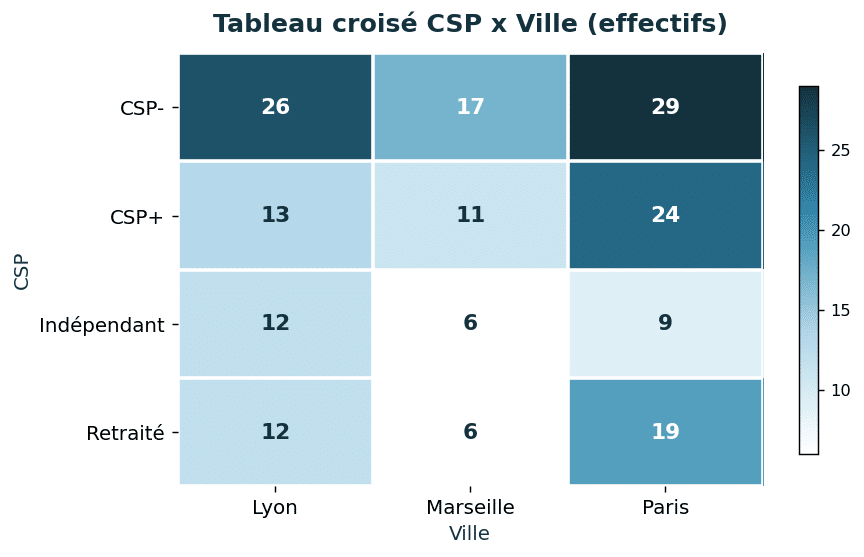
pd.crosstab(data["csp"], data["ville"])
Le résultat se lit comme un tableau à double entrée :
| csp | Lyon | Marseille | Paris |
|---|---|---|---|
| CSP+ | 13 | 11 | 24 |
| CSP- | 26 | 17 | 29 |
| Indépendant | 12 | 6 | 9 |
| Retraité | 12 | 6 | 19 |
On peut enrichir ce tableau, par exemple en ajoutant les totaux de lignes et de colonnes :
pd.crosstab(data["csp"], data["ville"], margins=True, margins_name="Total")
Ou en affichant des pourcentages en ligne plutôt que des effectifs, ce qui répond à la question « parmi les CSP-, quelle part habite chaque ville ? » :
(pd.crosstab(data["csp"], data["ville"], normalize="index") * 100).round(1)
ville Lyon Marseille Paris
csp
CSP+ 27.1 22.9 50.0
CSP- 36.1 23.6 40.3
Indépendant 44.4 22.2 33.3
Retraité 32.4 16.2 51.4
La seconde approche, pivot_table(), donne le même résultat avec une logique de tableau croisé dynamique :
data.pivot_table(index="csp", columns="ville", aggfunc="size", fill_value=0)
Le tri croisé avec R
En R, on réutilise tout simplement table() en lui passant les deux colonnes :
table(data$csp, data$ville)
Lyon Marseille Paris
CSP+ 13 11 24
CSP- 26 17 29
Indépendant 12 6 9
Retraité 12 6 19
Pour une analyse plus complète, le package gmodels fournit la fonction CrossTable(), qui donne des résultats proches de la proc freq de SAS (effectifs, pourcentages en ligne, en colonne et sur le total, et contribution au khi-deux) :
library(gmodels)
CrossTable(data$csp, data$ville)
Chaque case du tableau produit affiche alors plusieurs valeurs empilées : l’effectif, puis les pourcentages en ligne, en colonne et sur l’ensemble. C’est précieux pour interpréter finement un tableau croisé, mais l’affichage est dense, à réserver à l’analyse plutôt qu’à la présentation.
Visualiser un tableau croisé
Un tableau de contingence se prête très bien à une représentation graphique, souvent plus parlante qu’une grille de chiffres. Deux options simples et élégantes :
En Python, une heatmap (carte de chaleur) avec seaborn met en évidence les cases les plus remplies :
import seaborn as sns
import matplotlib.pyplot as plt
tableau = pd.crosstab(data["csp"], data["ville"])
sns.heatmap(tableau, annot=True, fmt="d", cmap="Blues")
plt.show()
En R, le ballon plot (ggballoonplot du package ggpubr) représente chaque effectif par un disque dont la taille et la couleur varient. C’est d’ailleurs le graphique élégant que l’on voit souvent en tête des articles sur les tableaux croisés :
library(ggpubr)
tableau <- as.data.frame(table(data$csp, data$ville))
ggballoonplot(tableau, x = "Var2", y = "Var1", size = "Freq", fill = "Freq")
Les données et le code
Le jeu de données et les scripts complets sont disponibles sur notre dépôt GitHub :
Découvrez nos formations Python et R
Le tri à plat et le tri croisé ne sont qu’un point de départ. Pour maîtriser l’analyse de données, de la statistique descriptive jusqu’aux modèles, nos formations vous accompagnent sur des cas concrets, avec des formateurs praticiens.
Côté Python, découvrez la formation Python pour la data science. Côté R, la formation logiciel R vous fait gagner en autonomie. Et pour la méthode, la formation statistique et analyse de données est faite pour vous. Une question ? Contactez-nous.
Formations data
Envie d’aller plus loin avec vos données ?
Du tri croisé jusqu’aux modèles, nous vous formons à la statistique, à Python et à R, sur des cas concrets et avec des formateurs praticiens. Choisissez votre porte d’entrée.
Statistique & analyse de données
Les méthodes pour décrire, tester et vraiment comprendre vos données.
Découvrir →Python pour la data science
L’écosystème Python data, de pandas jusqu’à la modélisation.
Découvrir →Logiciel R
Manipuler, visualiser et analyser vos données avec R, en autonomie.
Découvrir →Certifié Qualiopi, finançable OPCO Petits groupes, à distance ou à Paris Une question ? Contactez-nous
Partager cet article
Comments 3
J’ai aimé, en fait je suis doctorant en cote d’ivoire. je suis biochimiste je voudrais plus de formation si possible.
Bonjour,
Nous aimerions réaliser une représentation graphique de notre tableau de contingence. Pouvez-vous nous expliquer comment réaliser la représentation graphique située au début de votre article svp ?
Pouvons-nous également savoir comment elle se nomme ?
En vous remerciant
Bien cordialement
Chloé Party
Bonjour,
Il s’agit d’un ballon plot, vous trouverez une fonction pour l’exécuter ici : https://rpkgs.datanovia.com/ggpubr/reference/ggballoonplot.html
Bien cordialement,
Emmanuel Jakobowicz
Stat4decision