
À jour pour MLflow 3. Temps de lecture : environ 15 minutes.
Quand on développe des modèles de machine learning, on se retrouve vite avec un problème très concret. On lance un premier modèle, puis un deuxième avec d’autres paramètres, puis un troisième. Au bout de quelques jours, impossible de se souvenir lequel donnait les meilleurs résultats, ni avec quels réglages. Si on travaille en équipe, c’est encore pire.
MLflow répond exactement à ce besoin. Voyez le comme un cahier de laboratoire automatique pour vos projets de machine learning : il garde la trace de chaque essai, de chaque modèle et de chaque résultat, pour que vous puissiez comparer, retrouver et réutiliser votre travail en toute sérénité. C’est une plateforme open source initiée par Databricks, devenue aujourd’hui un standard du MLOps (la discipline qui consiste à industrialiser le machine learning).
Note de version. Cet article est à jour pour MLflow 3 (2025). Deux points ont changé par rapport aux anciens tutoriels, et nous les expliquons en détail plus bas : les stages du registre de modèles sont remplacés par des alias, et MLflow s’est ouvert à l’IA générative.
Tout le code de cet article est rassemblé dans un dépôt GitHub prêt à lancer. Vous pouvez le cloner, l’exécuter script par script et explorer les résultats dans l’interface MLflow. Le lien se trouve à la fin de l’article.
Un peu de vocabulaire pour bien démarrer
Trois mots reviennent en permanence dans MLflow. Mieux vaut les comprendre tout de suite.
- Une expérimentation (experiment) est un dossier logique qui regroupe tous les essais liés à un même objectif, par exemple « prédire la qualité d’un vin ».
- Un essai (run) est une exécution unique : un entraînement, avec ses paramètres et ses résultats. Une expérimentation contient plusieurs essais que vous pourrez comparer.
- Un artefact est un fichier produit pendant un essai et que MLflow conserve : le modèle entraîné, un graphique, un fichier de configuration, etc.
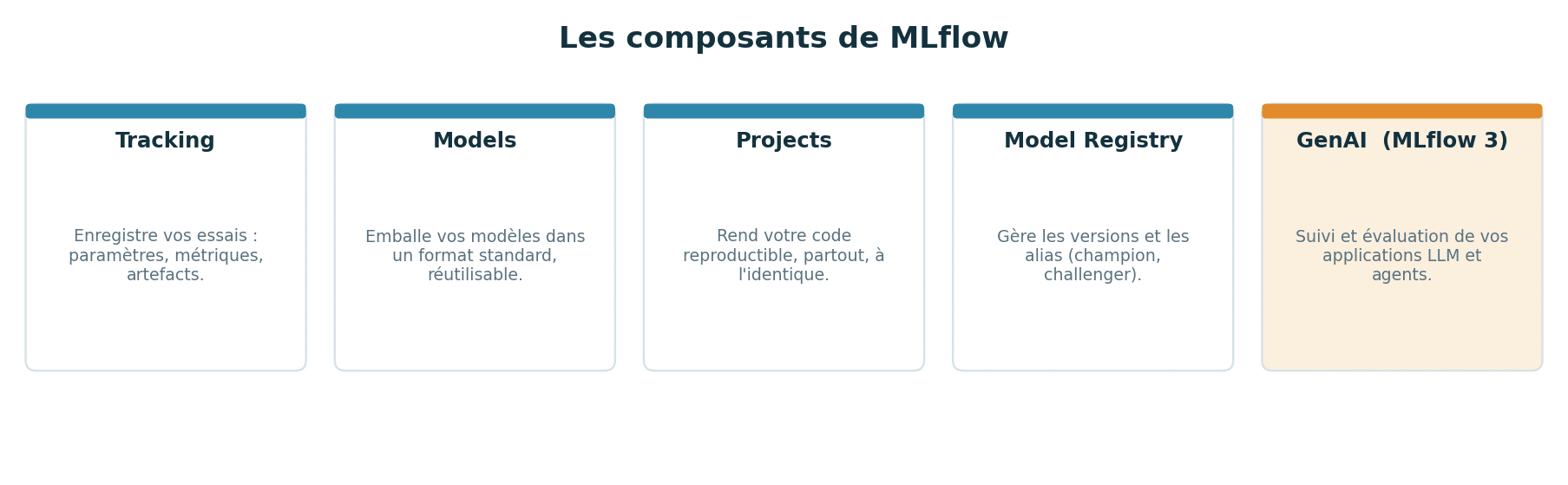
Les composants de MLflow
MLflow s’organise autour de quatre composants, auxquels MLflow 3 ajoute un volet dédié à l’IA générative. Voici à quoi sert chacun, en une phrase.
Le Tracking enregistre vos essais (paramètres, métriques, artefacts). Les Models packagent vos modèles dans un format standard pour les recharger ou les déployer facilement. Les Projects rendent votre code reproductible. Le Model Registry gère les versions de vos modèles et désigne ceux qui partent en production. Enfin, le volet GenAI de MLflow 3 vous aide à suivre et à évaluer vos applications à base de grands modèles de langage.
Nous allons les voir un par un, avec du code que vous pouvez exécuter.


Installation
L’installation tient en une ligne :
pip install mlflow scikit-learn pandas numpy
Tout au long de ce guide, nous utilisons le jeu de données des vins, fourni avec scikit-learn. Il est petit, propre, et parfait pour apprendre.
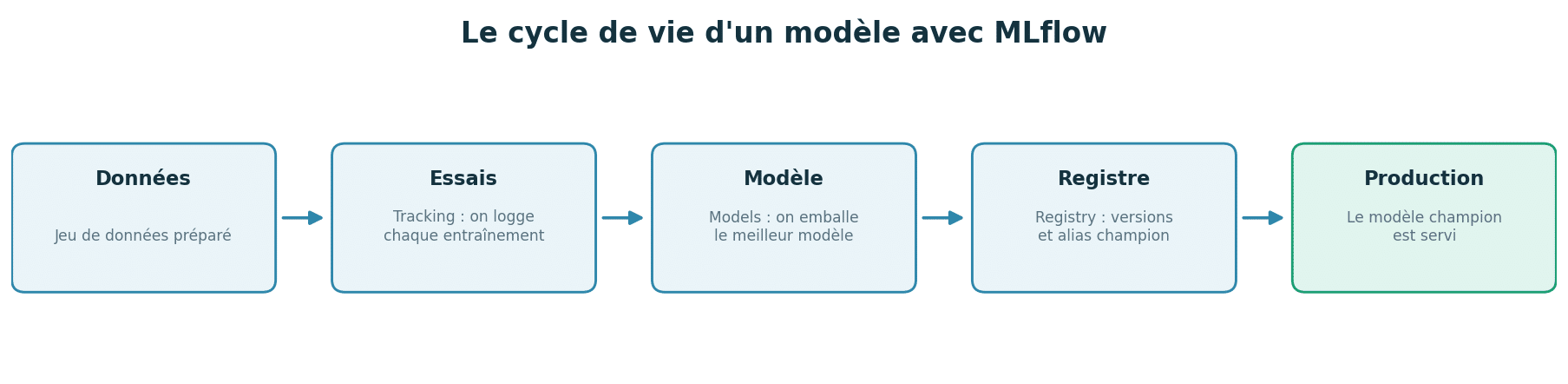
MLflow Tracking : garder la trace de vos essais
C’est le composant que vous utiliserez le plus. Commençons par le plus simple.
La façon la plus rapide de démarrer : l’autolog
Avant même d’écrire la moindre ligne de suivi, sachez que MLflow peut tout enregistrer pour vous, automatiquement. Cela s’appelle l’autolog, et cela fonctionne avec de nombreuses bibliothèques (scikit-learn, XGBoost, PyTorch, etc.).
import mlflow
from sklearn.datasets import load_wine
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
mlflow.set_experiment("classification_vins")
mlflow.sklearn.autolog() # la ligne magique : MLflow enregistre tout
X, y = load_wine(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
with mlflow.start_run(run_name="random_forest_autolog"):
model = RandomForestClassifier(n_estimators=100, max_depth=10, random_state=42)
model.fit(X_train, y_train)
Le bloc with mlflow.start_run(...) ouvre un essai, puis le referme proprement à la fin. Grâce à autolog(), les paramètres du modèle, ses métriques et le modèle lui même sont enregistrés sans aucun effort de votre part. C’est le réflexe à prendre dès vos premiers tests.
Enregistrer exactement ce que vous voulez
L’autolog couvre 80 pour cent des besoins. Mais dès que vous voulez tracer une métrique sur mesure, vous passez au suivi manuel. Voici le schéma type, commenté étape par étape.
import pandas as pd
from sklearn.metrics import accuracy_score, precision_score, recall_score
wine = load_wine()
X, y = wine.data, wine.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
def train_model(model_type, **params):
with mlflow.start_run(run_name=model_type):
# 1. On enregistre les paramètres de l'essai.
mlflow.log_params(params)
mlflow.log_param("model_type", model_type)
# 2. On entraîne le modèle.
model = RandomForestClassifier(**params, random_state=42)
model.fit(X_train, y_train)
# 3. On calcule et on enregistre les métriques.
y_pred = model.predict(X_test)
mlflow.log_metric("accuracy", accuracy_score(y_test, y_pred))
mlflow.log_metric("precision", precision_score(y_test, y_pred, average="weighted"))
mlflow.log_metric("recall", recall_score(y_test, y_pred, average="weighted"))
# 4. On enregistre le modèle. Depuis MLflow 3, le paramètre s'appelle "name"
# (il s'appelait "artifact_path" avant).
mlflow.sklearn.log_model(model, name="model")
train_model("RandomForest", n_estimators=200, max_depth=15)
Chaque appel à train_model crée un nouvel essai. En lançant la fonction avec plusieurs réglages, vous obtenez plusieurs essais que vous pourrez trier et comparer dans l’interface MLflow. (Insérez ici une capture de l’interface.)
MLflow Models : emballer un modèle pour le réutiliser
Entraîner un modèle, c’est bien. Pouvoir le recharger six mois plus tard sur une autre machine, c’est mieux. C’est le rôle du composant Models : il enregistre votre modèle dans un format standard, indépendant de l’outil qui l’a produit.
model = RandomForestClassifier(n_estimators=100, random_state=42).fit(X_train, y_train)
with mlflow.start_run():
mlflow.sklearn.log_model(
sk_model=model,
name="wine_classifier",
registered_model_name="WineClassifier",
# La signature décrit les entrées et sorties attendues du modèle.
# Elle documente le modèle et fiabilise son service en production.
signature=mlflow.models.infer_signature(X_train, model.predict(X_train)),
)
# Plus tard, on recharge le modèle en une ligne :
loaded = mlflow.sklearn.load_model("models:/WineClassifier/1")
print(loaded.predict(X_test)[:5])
La signature mérite une explication. C’est la carte d’identité des entrées et sorties du modèle (combien de colonnes, de quels types). Elle évite de mauvaises surprises au moment de servir le modèle, car MLflow peut vérifier que les données reçues ont bien la forme attendue.
Si votre modèle a besoin d’un traitement particulier avant de prédire (par exemple une normalisation), vous pouvez l’emballer avec ce traitement grâce à un modèle PyFunc personnalisé. L’exemple complet se trouve dans le dépôt GitHub (src/03_models.py).
MLflow Projects : rendre votre code reproductible
Un projet qui tourne sur votre machine ne tourne pas forcément sur celle de votre collègue, faute du même environnement. MLflow Projects résout ce souci en décrivant, dans un fichier, le code à exécuter et l’environnement dont il a besoin.
Vous créez un fichier MLproject qui liste les points d’entrée et les paramètres :
name: wine-classification
python_env: python_env.yaml
entry_points:
main:
parameters:
n_estimators: {type: int, default: 100}
max_depth: {type: int, default: 10}
command: "python train.py --n-estimators {n_estimators} --max-depth {max_depth}"
Et un fichier python_env.yaml qui fige les versions, pour que tout le monde installe exactement le même environnement :
python: "3.11"
dependencies:
- scikit-learn==1.5.2
- pandas==2.2.3
- mlflow>=3.1
Vous pouvez alors relancer l’entraînement de façon identique, en local ou directement depuis un dépôt Git :
mlflow.run(".", parameters={"n_estimators": 200, "max_depth": 15})
Le script train.py correspondant est dans le dépôt GitHub.
MLflow Model Registry : gérer les versions avec des alias
Au fil des semaines, vous allez produire plusieurs versions d’un même modèle. Le Model Registry est l’endroit où vous les centralisez, les annotez, et où vous désignez celle qui part en production.
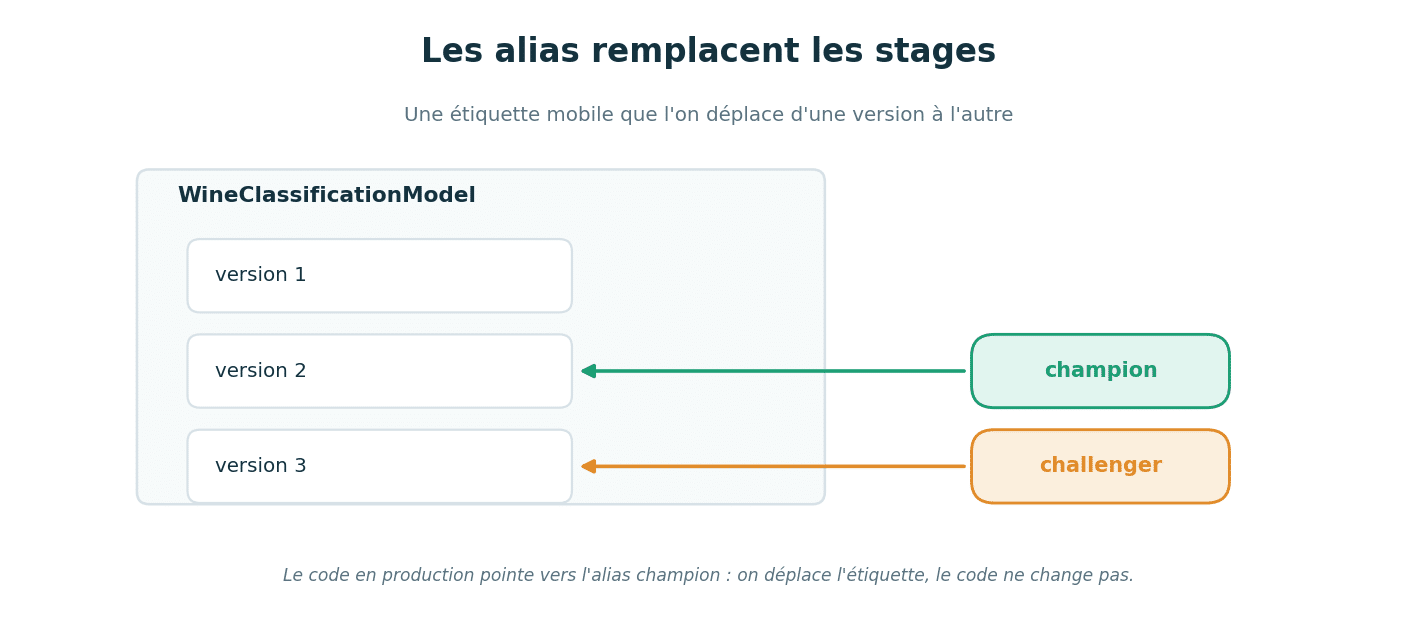
Le point important à connaître. Beaucoup d’anciens tutoriels promeuvent les modèles vers des stages nommés Staging et Production. Ce mécanisme est déprécié depuis MLflow 2.9. Il est remplacé par les alias, plus souples. Un alias est une étiquette mobile que vous posez sur une version précise. La grande différence : vous pouvez poser plusieurs alias, et les déplacer d’une version à l’autre quand vous le souhaitez.
L’analogie est simple. Plutôt que de ranger un modèle dans une case fixe « production », vous lui collez une étiquette champion (le modèle actuellement servi) ou challenger (un candidat à tester). Quand un challenger se révèle meilleur, vous déplacez l’étiquette champion sur sa version. Votre code en production, lui, ne change pas, car il pointe simplement vers l’alias champion.

from mlflow import MlflowClient
client = MlflowClient()
model_name = "WineClassificationModel"
# On enregistre une version du modèle.
with mlflow.start_run():
model = RandomForestClassifier(n_estimators=100, random_state=42).fit(X_train, y_train)
mlflow.sklearn.log_model(model, name="model", registered_model_name=model_name)
# On pose l'alias "challenger" sur la version 1 (un candidat).
client.set_registered_model_alias(name=model_name, alias="challenger", version=1)
# On annote et on tague la version pour garder une trace de sa validation.
client.update_model_version(name=model_name, version=1,
description="Classification des vins, RandomForest")
client.set_model_version_tag(name=model_name, version=1,
key="validation_status", value="passed")
# Après validation, on promeut la version en "champion".
client.set_registered_model_alias(name=model_name, alias="champion", version=1)
Le chargement se fait alors par alias. Notez le caractère @ dans l’adresse du modèle, qui désigne un alias :
champion = mlflow.sklearn.load_model(f"models:/{model_name}@champion")
Si vous utilisez Databricks, le registre vit désormais dans Unity Catalog. Vous l’activez avec mlflow.set_registry_uri("databricks-uc"), et vos modèles portent un nom à trois niveaux (catalogue.schema.modele). Vous gagnez alors le contrôle d’accès, la traçabilité de l’origine des données et le partage des modèles entre équipes.
MLflow et l’IA générative (nouveauté de MLflow 3)
Voici la grande évolution récente. MLflow 3 a été repensé pour la GenAI. Au delà du machine learning classique, il vous aide désormais à développer et à fiabiliser des applications construites autour de grands modèles de langage et d’agents.
Trois capacités à retenir. Le tracing enregistre automatiquement chaque appel à un modèle de langage : la question posée, la réponse, le temps de calcul, et les étapes intermédiaires d’un agent. C’est précieux pour comprendre ce qui se passe réellement et déboguer. L’évaluation mesure la qualité des réponses (pertinence, fidélité aux sources, sécurité) à l’aide de critères automatiques. Le registre de prompts vous permet de versionner vos prompts comme vous versionnez votre code.
Activer le tracing tient en une ligne, par bibliothèque :
import mlflow
mlflow.openai.autolog() # trace automatiquement les appels OpenAI
Vous pouvez aussi instrumenter vos propres fonctions avec un décorateur :
@mlflow.trace
def repondre(question: str) -> str:
# votre logique d'appel au modèle de langage ici
return reponse
Bonne nouvelle : ces traces s’affichent dans la même interface que vos expérimentations classiques. Les équipes qui mélangent machine learning et IA générative gardent ainsi un seul outil.
Quelques bonnes pratiques
Donnez des noms clairs à vos essais et ajoutez des tags cohérents (équipe, projet, phase). C’est ce qui rend votre travail exploitable quand les essais se comptent par centaines.
Attention à une erreur fréquente lors du nettoyage de vos anciennes expérimentations. La fonction list_experiments() a été supprimée dans MLflow 2.0. Utilisez search_experiments() à la place :
from mlflow import MlflowClient
client = MlflowClient()
for exp in client.search_experiments(): # et non list_experiments()
if "old" in exp.name.lower():
client.delete_experiment(exp.experiment_id)
Enfin, prenez l’habitude d’activer l’autolog dès le prototypage, d’ajouter une signature à vos modèles, et d’intégrer MLflow dans vos chaînes d’intégration continue pour automatiser entraînement, validation et promotion d’alias.
Lancer l’interface MLflow
Pour visualiser tout votre travail dans un navigateur :
mlflow ui --backend-store-uri sqlite:///mlflow.db
Vous y retrouverez vos expérimentations, vos modèles, leurs alias et vos traces, le tout dans une seule fenêtre.
Le code complet de cet article
Tous les exemples de ce guide sont rassemblés dans un dépôt GitHub, organisés en scripts numérotés que vous pouvez lancer dans l’ordre :
https://www.github.com/stat4decision/mlflow-post
Chaque script est court et commenté. Le dépôt contient aussi le projet reproductible (MLproject) et un fichier d’installation. Clonez le, lancez les exemples, et explorez vos résultats dans l’interface MLflow.
Conclusion
MLflow est devenu un outil incontournable pour professionnaliser ses pratiques de machine learning. En réunissant le suivi des essais, le packaging des modèles, la reproductibilité du code et la gestion des versions, et maintenant l’observabilité de l’IA générative, il vous fait gagner du temps et améliore nettement la qualité de vos projets.
Si vous ne deviez retenir que cinq points :
- Activez le suivi, et surtout l’autolog, dès vos premiers essais.
- Standardisez vos modèles avec une signature.
- Adoptez les projets MLflow pour la reproductibilité.
- Gérez vos modèles avec des alias plutôt que des stages, et via Unity Catalog sur Databricks.
- Avec MLflow 3, étendez ces bonnes pratiques à vos applications de langage et à vos agents.
Maîtrisez MLflow et le MLOps avec Stat4decision
Vous souhaitez professionnaliser vos projets de machine learning et adopter directement les bons réflexes ? Nous formons des équipes data au quotidien, sur des cas concrets et sur vos propres données.
- Formation Databricks : MLflow dans l’écosystème Databricks, modèles dans Unity Catalog, déploiement et intégration Delta Lake.
- Python pour la data science : maîtriser l’écosystème Python data de bout en bout.
- scikit-learn pour le machine learning : construire des modèles robustes avec des pipelines propres.
Petits groupes de 8 participants au maximum, à distance ou à Paris, certifié Qualiopi et finançable par les OPCO. Prochaines dates et tarifs sur nos pages formation, ou contactez nous pour une session sur mesure.
Partager cet article