
L’intelligence artificielle est passée en quelques années du laboratoire de recherche aux outils du quotidien : moteurs de recommandation, scoring de crédit, tri de candidatures, assistants conversationnels, génération d’images. Cette diffusion massive a poussé l’Union européenne à se doter d’un cadre juridique dédié. C’est l’objet de l’AI Act (officiellement le règlement UE 2024/1689), le premier texte au monde à réguler l’IA de façon transversale et contraignante.
Pour celles et ceux qui conçoivent, entraînent ou déploient des modèles, ce règlement n’est pas une simple formalité juridique. Il redéfinit les obligations qui pèsent sur les systèmes de machine learning selon l’usage qui en est fait, et il formalise une bonne partie des exigences que la rigueur statistique recommande déjà : qualité des données, contrôle des biais, traçabilité, évaluation des performances. Cet article propose une présentation pédagogique du texte, avec un fil rouge tourné vers le travail des équipes data.
Avertissement : cet article a une vocation pédagogique et ne constitue pas un avis juridique. Le calendrier de l’AI Act a fait l’objet d’ajustements politiques au printemps 2026 (le « Digital Omnibus ») encore en cours de finalisation au moment de la rédaction. Pour toute décision de mise en conformité, référez-vous aux textes officiels et à un conseil spécialisé.
1. Qu’est-ce que l’AI Act ?
L’AI Act est un règlement européen adopté le 13 juin 2024 et entré en vigueur le 1er août 2024. Étant un règlement (et non une directive), il s’applique directement dans tous les États membres, sans transposition nationale.
Trois caractéristiques résument sa philosophie :
- Un cadre horizontal : il ne vise pas un secteur particulier mais l’IA en tant que technologie, quel que soit le domaine d’application (santé, finance, RH, industrie).
- Une approche fondée sur le risque : plutôt que d’interdire ou d’autoriser en bloc, le texte module les obligations en fonction du danger que représente chaque usage pour la sécurité et les droits fondamentaux.
- Une application progressive : les obligations entrent en vigueur par paliers successifs entre 2025 et 2028, pour laisser aux acteurs le temps de s’adapter.
L’objectif affiché est double : protéger les citoyens européens contre les usages problématiques de l’IA, tout en créant un environnement de confiance favorable à l’innovation.
2. Qui est concerné ?
Le champ d’application de l’AI Act est large et, point essentiel, extraterritorial. Le règlement s’applique dès lors qu’un système d’IA est mis sur le marché, mis en service ou utilisé dans l’Union européenne, même si l’entreprise qui le fournit est établie hors d’Europe. Un éditeur américain ou asiatique dont les systèmes touchent des utilisateurs européens entre donc dans le périmètre.
Le texte distingue plusieurs rôles, et les obligations diffèrent selon celui que l’on occupe :
- Le fournisseur (provider) : celui qui développe un système d’IA et le met sur le marché sous son nom. C’est lui qui porte l’essentiel des obligations techniques. Une équipe data qui entraîne un modèle en interne et le met en production occupe souvent ce rôle.
- Le déployeur (deployer) : toute organisation qui utilise un système d’IA dans le cadre de son activité professionnelle. Dès qu’une entreprise se sert d’un outil d’IA pour son fonctionnement, elle est déployeur et porte des obligations propres.
- L’importateur et le distributeur : les acteurs qui font circuler sur le marché européen un système d’IA conçu par un tiers.
Cette distinction est cruciale, car une même structure peut cumuler les casquettes : développer un modèle maison (fournisseur) tout en consommant des API tierces (déployeur). À noter aussi qu’un déployeur peut basculer dans le statut de fournisseur s’il modifie substantiellement un système ou le rebaptise sous son propre nom, un point à surveiller dès lors qu’on fine-tune un modèle existant.
3. Comment l’AI Act définit-il un « système d’IA » ?
Avant d’appliquer la moindre obligation, encore faut-il savoir ce qui compte comme « IA ». L’article 3 du règlement retient une définition volontairement large, alignée sur celle de l’OCDE : un système d’IA est un système automatisé qui, à partir des entrées qu’il reçoit, infère comment produire des sorties (prédictions, recommandations, contenus, décisions) capables d’influencer des environnements physiques ou virtuels, avec un certain degré d’autonomie et une capacité d’adaptation.
Le mot-clé est inférence. Cette formulation englobe l’apprentissage automatique au sens large : régression, arbres, gradient boosting, réseaux de neurones, modèles génératifs. Elle vise en revanche à exclure les logiciels purement déterministes, comme un simple calcul sur tableur ou un système de règles figées qui se contente d’appliquer mécaniquement des instructions écrites par un humain. La frontière reste parfois floue, ce qui fait de la qualification du système la première étape, et l’une des plus délicates, de toute démarche de conformité.
https://eur-lex.europa.eu/eli/reg/2024/1689/oj?locale=fr
4. Le cœur du dispositif : l’approche par les risques
C’est la colonne vertébrale du règlement. L’AI Act classe les systèmes d’IA en quatre niveaux de risque, souvent représentés sous forme de pyramide. Plus le risque pour les personnes est élevé, plus les contraintes sont lourdes.
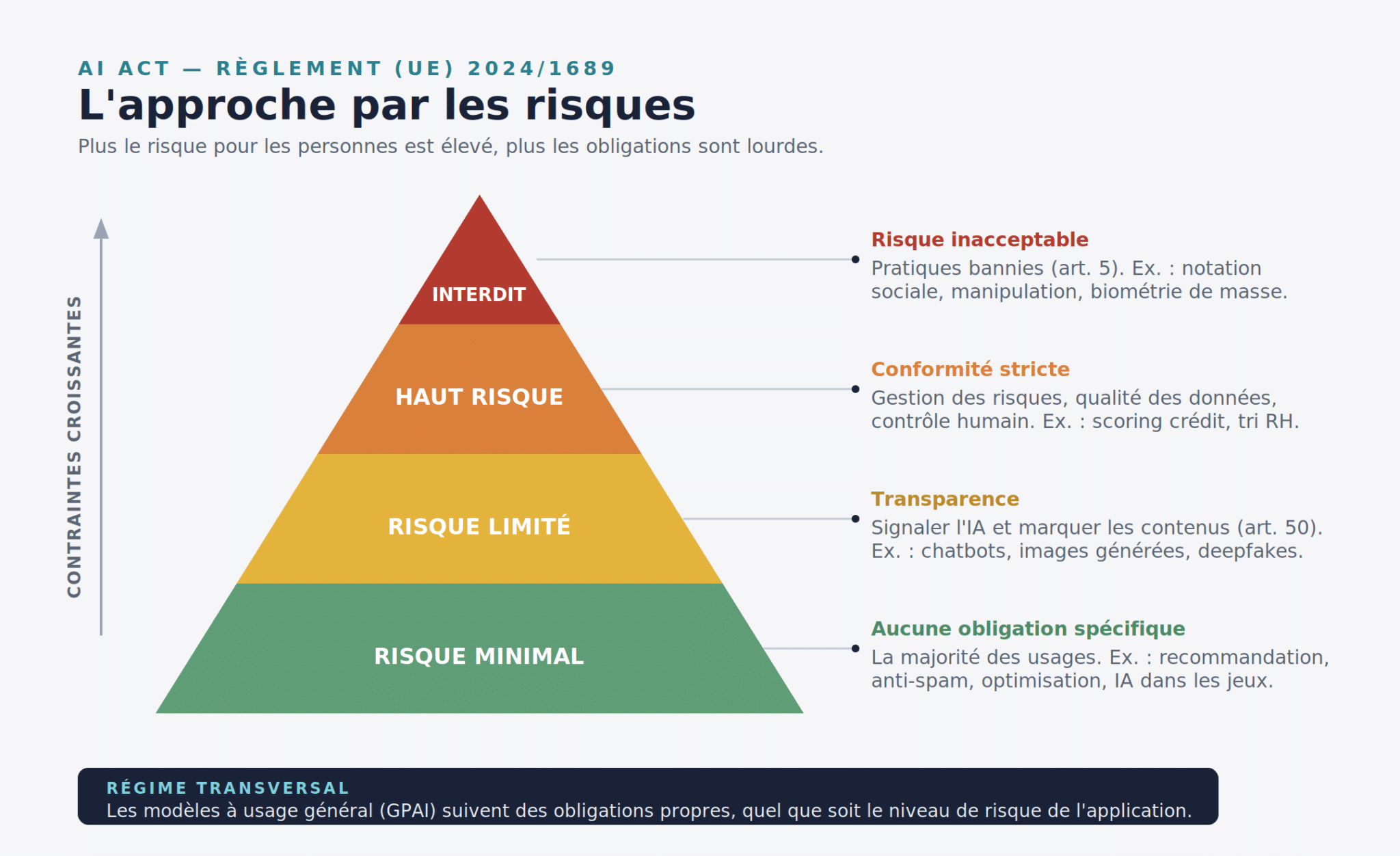

Les quatre niveaux de risque de l’AI Act, et le régime transversal des modèles à usage général.
Niveau 1 : risque inacceptable, les pratiques interdites
Au sommet de la pyramide, certaines pratiques sont jugées contraires aux valeurs fondamentales de l’Union et purement interdites, sans possibilité de mise en conformité. Elles sont listées à l’article 5 et prohibées depuis le 2 février 2025. On y trouve notamment :
- les techniques de manipulation subliminale destinées à altérer substantiellement le comportement d’une personne à son détriment ;
- l’exploitation des vulnérabilités liées à l’âge, au handicap ou à une situation socio-économique ;
- la notation sociale généralisée des individus par les autorités (le « social scoring ») ;
- la police prédictive individuelle fondée uniquement sur le profilage ou les traits de personnalité ;
- le moissonnage non ciblé d’images faciales pour constituer des bases de reconnaissance faciale ;
- la reconnaissance des émotions sur le lieu de travail et à l’école (sauf usages médicaux ou de sécurité) ;
- la catégorisation biométrique déduisant des données sensibles (origine, opinions politiques, religion, orientation sexuelle) ;
- l’identification biométrique à distance en temps réel dans les espaces publics à des fins répressives, sauf exceptions strictement encadrées.
Ces interdictions s’imposent à la fois aux fournisseurs et aux déployeurs.
Niveau 2 : haut risque, l’encadrement strict
Les systèmes à haut risque ne sont pas interdits, mais soumis à un régime de conformité rigoureux. Deux grandes familles sont concernées :
- Les IA intégrées comme composant de sécurité dans des produits déjà réglementés (machines, dispositifs médicaux, jouets, ascenseurs, automobiles), couverts par l’annexe I.
- Les IA utilisées dans des domaines critiques listés à l’annexe III : biométrie, infrastructures critiques, éducation, emploi et ressources humaines (tri de CV, évaluation des candidats), accès aux services essentiels (dont le scoring de crédit), maintien de l’ordre, migration et asile, justice.
C’est cette catégorie qui concerne le plus directement de nombreux projets data en entreprise : un modèle de scoring de solvabilité ou un algorithme de présélection de candidatures relève typiquement du haut risque. Les obligations associées sont détaillées plus bas.
Niveau 3 : risque limité, la transparence
Certains systèmes ne sont pas dangereux en eux-mêmes mais peuvent tromper l’utilisateur sur la nature de ce avec quoi il interagit. L’article 50 leur impose des obligations de transparence ciblées. C’est sans doute le volet qui touchera le plus grand nombre d’organisations, car il vise l’IA générative dans son ensemble :
- un chatbot ou un assistant vocal doit signaler clairement qu’il s’agit d’une machine, et non d’un humain (sauf si c’est évident dans le contexte) ;
- les contenus synthétiques générés par IA (texte, image, son, vidéo) doivent être marqués comme tels, de façon lisible par machine ;
- les deepfakes doivent être explicitement signalés (un régime allégé existe pour les œuvres manifestement artistiques ou satiriques) ;
- l’usage de systèmes de reconnaissance des émotions ou de catégorisation biométrique, quand ils ne sont pas interdits, doit être porté à la connaissance des personnes.
Niveau 4 : risque minimal, la liberté encadrée
À la base de la pyramide se trouve l’immense majorité des usages : filtres anti-spam, moteurs de recommandation, IA dans les jeux vidéo, optimisation logistique. Ces systèmes ne sont soumis à aucune obligation spécifique au titre de l’AI Act, au-delà de l’obligation transversale de littératie en IA (voir plus bas). Ils restent bien sûr soumis aux autres réglementations applicables (RGPD, droit du travail, droit d’auteur).
5. Le cas particulier des modèles à usage général (GPAI)
L’arrivée fulgurante des grands modèles de langage a conduit le législateur à créer un régime distinct, qui se superpose à la classification par les risques : celui des modèles d’IA à usage général (General Purpose AI, ou GPAI). Il s’agit des modèles socles entraînés sur de vastes corpus et réutilisables pour une multitude de tâches, typiquement les grands modèles génératifs.
Les fournisseurs de GPAI sont soumis depuis le 2 août 2025 à des obligations propres :
- constituer et tenir à jour une documentation technique du modèle ;
- fournir aux acteurs en aval (ceux qui intègrent le modèle dans leurs applications) les informations nécessaires ;
- respecter le droit d’auteur dans la collecte des données d’entraînement ;
- publier un résumé suffisamment détaillé des contenus utilisés pour l’entraînement.
Une sous-catégorie est identifiée comme présentant un risque systémique : les modèles les plus puissants, repérés notamment par la puissance de calcul mobilisée pour leur entraînement (un seuil exprimé en opérations en virgule flottante, ou FLOP). Ces modèles supportent des obligations renforcées : évaluation des risques, tests adverses, signalement des incidents graves, mesures de cybersécurité. Pour une équipe qui intègre ou affine un modèle open weight, ce régime n’est pas qu’une affaire de fournisseurs : il conditionne les informations disponibles en amont de votre propre chaîne de traitement.
6. Que doit faire concrètement un système à haut risque ?
Pour les systèmes classés à haut risque, le règlement détaille un ensemble d’exigences techniques et organisationnelles (articles 9 à 27). Les principales :
- Système de gestion des risques (art. 9) : identifier, évaluer et atténuer les risques tout au long du cycle de vie du modèle.
- Gouvernance des données (art. 10) : utiliser des jeux d’entraînement, de validation et de test pertinents, représentatifs et, autant que possible, exempts de biais.
- Documentation technique (art. 11, annexe IV) : décrire la conception, le fonctionnement et les performances du système.
- Traçabilité et journalisation (art. 12) : enregistrer automatiquement les événements (logs) pour permettre le suivi et l’audit.
- Transparence vis-à-vis du déployeur (art. 13) : fournir une notice d’utilisation claire.
- Contrôle humain (art. 14) : concevoir le système pour qu’un humain puisse comprendre, superviser et, si besoin, interrompre son fonctionnement.
- Exactitude, robustesse et cybersécurité (art. 15).
- Marquage CE, enregistrement dans la base de données européenne, et évaluation de conformité avant la mise sur le marché.
Côté déployeur s’ajoute notamment l’analyse d’impact sur les droits fondamentaux (FRIA, art. 27) pour certains usages, ainsi que des obligations de surveillance et d’information des personnes concernées.
7. Ce que l’AI Act change pour les équipes data
C’est le point qui intéresse le plus directement les data scientists et analystes : derrière le vocabulaire juridique, les exigences du haut risque se traduisent en pratiques concrètes de data science et de MLOps. La plupart relèvent de l’artisanat bien fait, mais le règlement les rend opposables et documentables.
Qualité et représentativité des données (art. 10). L’exigence de jeux de données pertinents et peu biaisés place l’analyse exploratoire, l’audit des biais et l’équité algorithmique au cœur de la conformité. Concrètement : vérifier la couverture des sous-populations, mesurer les écarts de performance entre groupes (par exemple via des métriques de fairness), documenter les choix d’échantillonnage et les retraitements. Un modèle de scoring qui sous-performe sur un segment de la population n’est plus seulement un problème de qualité, c’est un risque de conformité.
Documentation du modèle (art. 11). La documentation technique attendue recoupe largement les pratiques de model cards et de datasheets for datasets : objectif du modèle, données utilisées, méthodologie d’entraînement, métriques de performance, limites connues. Tenir cette documentation à jour au fil des itérations, plutôt que de la reconstituer après coup, fait gagner un temps considérable.
Traçabilité et reproductibilité (art. 12). La journalisation automatique rejoint les bonnes pratiques MLOps : versionnage des données et des modèles, suivi des expériences, enregistrement des prédictions en production. Un pipeline reproductible, où l’on sait quelle version de données a produit quel modèle, est la meilleure réponse à une demande d’audit.
Contrôle humain (art. 14). Concevoir le human-in-the-loop devient une exigence : seuils de confiance déclenchant une revue manuelle, possibilité de surcharger une décision automatisée, interfaces qui rendent la sortie du modèle intelligible pour l’opérateur. L’explicabilité (importance des variables, méthodes d’interprétation locale) trouve ici une justification directe.
Robustesse et performance (art. 15). Au-delà de l’exactitude moyenne, le texte invite à éprouver la robustesse : comportement sur des cas limites, stabilité face à des entrées dégradées ou adverses, gestion des valeurs aberrantes. Les protocoles de validation et de test prennent une dimension réglementaire.
Surveillance après déploiement. Un modèle n’est jamais figé. La surveillance de la dérive (data drift, concept drift), le monitoring des performances en production et les procédures de réentraînement deviennent des éléments de conformité, et plus seulement de maintenance.
Si vous travaillez avec des LLM. L’intégration ou le fine-tuning de modèles génératifs combine plusieurs régimes : transparence côté sorties (art. 50), vigilance sur le droit d’auteur et les données d’entraînement, et attention au moment où une adaptation substantielle vous ferait endosser le rôle de fournisseur.
En somme, l’AI Act récompense les équipes qui ont déjà investi dans une démarche rigoureuse et outillée. La conformité se construit dans le pipeline, pas dans un document rédigé à la fin du projet.
8. Une obligation pour tous : la littératie en IA
Souvent négligé, l’article 4 mérite l’attention car il s’applique à tous les acteurs, quel que soit le niveau de risque. Il impose aux fournisseurs et aux déployeurs de veiller à ce que leur personnel, et toute personne intervenant sur les systèmes d’IA pour leur compte, dispose d’un niveau suffisant de maîtrise de l’IA : comprendre comment ces systèmes fonctionnent, leurs limites, leurs risques et la façon de les utiliser à bon escient.
En pratique, cela passe par la formation et la sensibilisation des équipes. C’est probablement le point d’entrée le plus immédiat pour les organisations qui souhaitent amorcer leur mise en conformité, et il est déjà applicable.
9. Le calendrier d’application
L’AI Act s’applique par paliers. Le Digital Omnibus, paquet de simplification ayant fait l’objet d’un accord politique provisoire entre le Conseil et le Parlement le 7 mai 2026, a redessiné certaines échéances pour les systèmes à haut risque.

Le déploiement échelonné des obligations, avec les reports proposés par le Digital Omnibus.
Point de vigilance important : au moment de la rédaction, le Digital Omnibus reste un accord provisoire, qui doit encore être formellement adopté (votes au Parlement, adoption par le Conseil, publication au Journal officiel). S’il n’est pas adopté avant le 2 août 2026, c’est le calendrier initial qui s’applique, avec une entrée en vigueur des obligations haut risque dès cet été. Par ailleurs, certaines nouvelles obligations attendues séparément (comme l’interdiction des applications de type « nudifier » et le marquage des contenus générés) ne sont pas concernées par ces reports. La prudence consiste donc à ne pas suspendre les travaux de cartographie et de documentation en pariant sur le report.
10. Les sanctions
Le régime de sanctions est calqué, dans sa logique, sur celui du RGPD, avec des plafonds calculés au plus fort des deux montants suivants :
- Pratiques interdites (art. 5) : jusqu’à 35 millions d’euros ou 7 % du chiffre d’affaires annuel mondial.
- Autres manquements (obligations haut risque, transparence) : jusqu’à 15 millions d’euros ou 3 % du chiffre d’affaires mondial.
- Informations inexactes fournies aux autorités : jusqu’à 7,5 millions d’euros ou 1 %.
Des plafonds adaptés et plus cléments sont prévus pour les PME et, depuis le Digital Omnibus, ces facilités sont étendues à un périmètre plus large d’entreprises de taille intermédiaire.
11. Quelle articulation avec le RGPD ?
C’est une question fréquente, car les deux textes se recoupent sans se confondre. Le RGPD régit le traitement des données à caractère personnel. L’AI Act régit les systèmes d’IA en tant que tels, qu’ils traitent ou non des données personnelles.
Les deux peuvent donc s’appliquer simultanément : un système de scoring de crédit traite des données personnelles (RGPD) et constitue un système à haut risque (AI Act). Ils sont complémentaires plutôt que redondants. L’article 22 du RGPD, qui encadre les décisions entièrement automatisées, conserve par exemple toute sa pertinence en parallèle des obligations de l’AI Act.
12. Qui contrôle ? La gouvernance
La supervision s’organise sur deux niveaux. Au niveau européen, le Bureau de l’IA (AI Office), rattaché à la Commission, supervise notamment les modèles à usage général et coordonne l’application du règlement. Au niveau national, chaque État membre désigne des autorités compétentes. En France, la CNIL est en première ligne, en particulier sur les sujets croisés avec le RGPD, aux côtés d’autres autorités sectorielles selon les domaines (l’Arcom pour certains contenus, la DGCCRF pour la surveillance du marché des produits).
Que faire concrètement ? Une feuille de route
Au-delà de la théorie, voici les premiers réflexes utiles pour une organisation qui développe ou utilise de l’IA :
- Cartographier l’ensemble des systèmes d’IA développés ou utilisés (y compris les outils SaaS et les API tierces). On en découvre souvent plus que prévu.
- Qualifier chaque système : relève-t-il d’une pratique interdite ? d’un usage à haut risque de l’annexe III ? d’une obligation de transparence ? Documenter cette qualification par écrit, avec date et responsable.
- Identifier son rôle (fournisseur, déployeur ou les deux) pour chaque système.
- Former les équipes au titre de la littératie en IA (art. 4), déjà applicable.
- Outiller le pipeline : audit des biais, documentation des modèles, versionnage, journalisation et monitoring, autant de chantiers à anticiper pour les systèmes à haut risque.
- Refaire l’exercice régulièrement : un système anodin aujourd’hui peut devenir à haut risque demain si son usage évolue, par exemple un chatbot commercial réorienté vers le tri de candidatures.
En résumé
L’AI Act inaugure une nouvelle ère pour les professionnels de la donnée. Sa logique est claire et proportionnée : la grande majorité des usages reste libre, une minorité sensible est encadrée, et quelques pratiques sont bannies. Pour les data scientists, les exigences sur la qualité et la gouvernance des données, la traçabilité et le contrôle humain ne sont pas étrangères au métier : elles formalisent des bonnes pratiques que la rigueur statistique recommande déjà.
L’enjeu des prochains mois n’est pas tant la date exacte d’entrée en vigueur de telle ou telle obligation, le calendrier restant mouvant, que la mise en place d’une démarche structurée. Cartographier, qualifier, documenter, outiller et former : voilà le socle d’une IA à la fois conforme et digne de confiance.
Partager cet article