
La croissance exponentielle des données et de l’IA pousse les entreprises à adopter des plateformes performantes pour exploiter tout le potentiel de leurs informations. Ces dernières années, Databricks s’est imposé comme l’une des solutions phares unifiant la data science, l’ingénierie des données et l’analytique big data dans un environnement collaboratif unique.
Cet article vous propose un tour d’horizon technique et pédagogique de l’écosystème Databricks. Vous découvrirez ce qu’est Databricks, comment cette plateforme fonctionne, quels sont ses composants clés, ainsi que des cas d’usage concrets illustrant la valeur qu’elle peut apporter aux équipes métier et techniques en entreprise. Nous aborderons également les possibilités d’intégration de Databricks dans le SI existant, et les points de vigilance à connaître pour réussir son adoption.
Qu’est-ce que Databricks ?
Databricks est une plateforme unifiée d’analytique et d’AI (intelligence artificielle) dans le cloud, initialement créée par les fondateurs d’Apache Spark. Elle vise à simplifier la gestion des pipelines de données volumineuses et des projets de machine learning. Concrètement, Databricks réunit en un seul endroit les besoins de data engineering, de data science et d’analytique business sur les données massives. Elle offre une interface collaborative de notebooks partagés, repose sur des clusters Spark managés (aucune gestion d’infrastructure complexe à votre charge) et intègre des outils avancés pour le machine learning. L’objectif est de permettre aux équipes données de se concentrer sur l’analyse et l’innovation, plutôt que sur la mise en place technique.
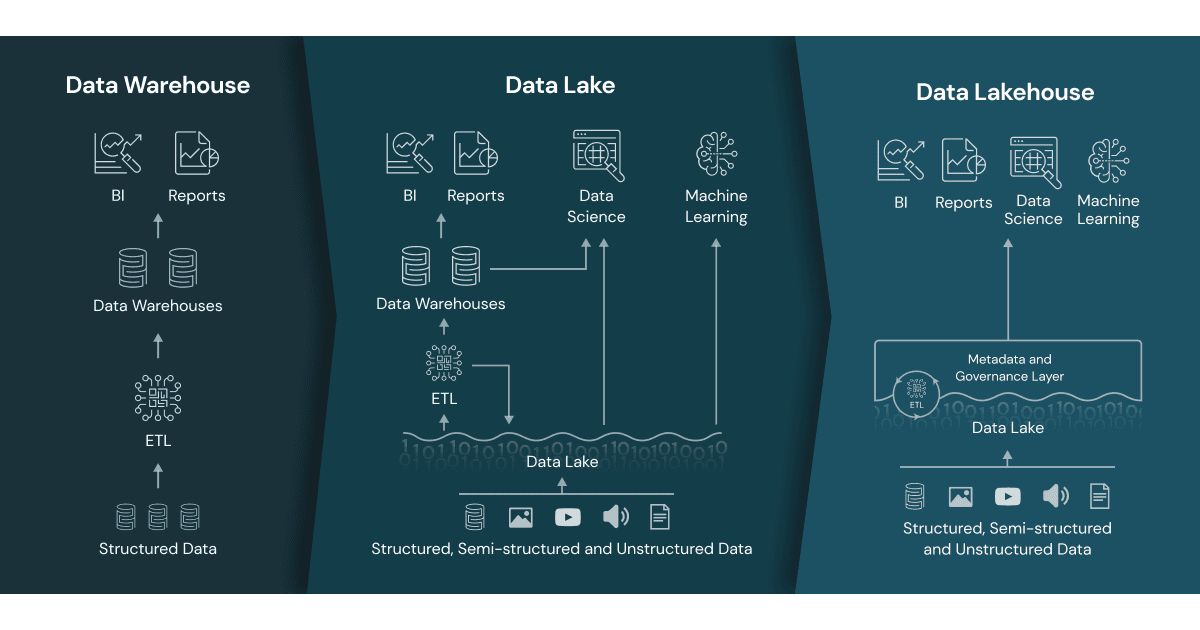
Une notion clé introduite par Databricks est celle de Lakehouse. Il s’agit d’une architecture de stockage unifiant les atouts d’un data lake et d’un data warehouse classique. En effet, Databricks combine la flexibilité et l’évolutivité d’un lac de données avec la structure et les fonctionnalités de gestion d’un entrepôt de données, au sein d’une plateforme unique et ouverte. Cette approche “lakehouse” permet de stocker tous types de données (structurées, semi-structurées, brutes) comme dans un data lake, tout en garantissant la qualité, la fiabilité et les performances d’un entrepôt de données traditionnel pour les requêtes SQL et analyses. En somme, la plateforme Databricks vise à éliminer les silos entre data engineers, data scientists et analystes, afin qu’ils collaborent sur les mêmes données et outils, et à démocratiser l’accès à la donnée et à l’analytique avancée dans l’entreprise.
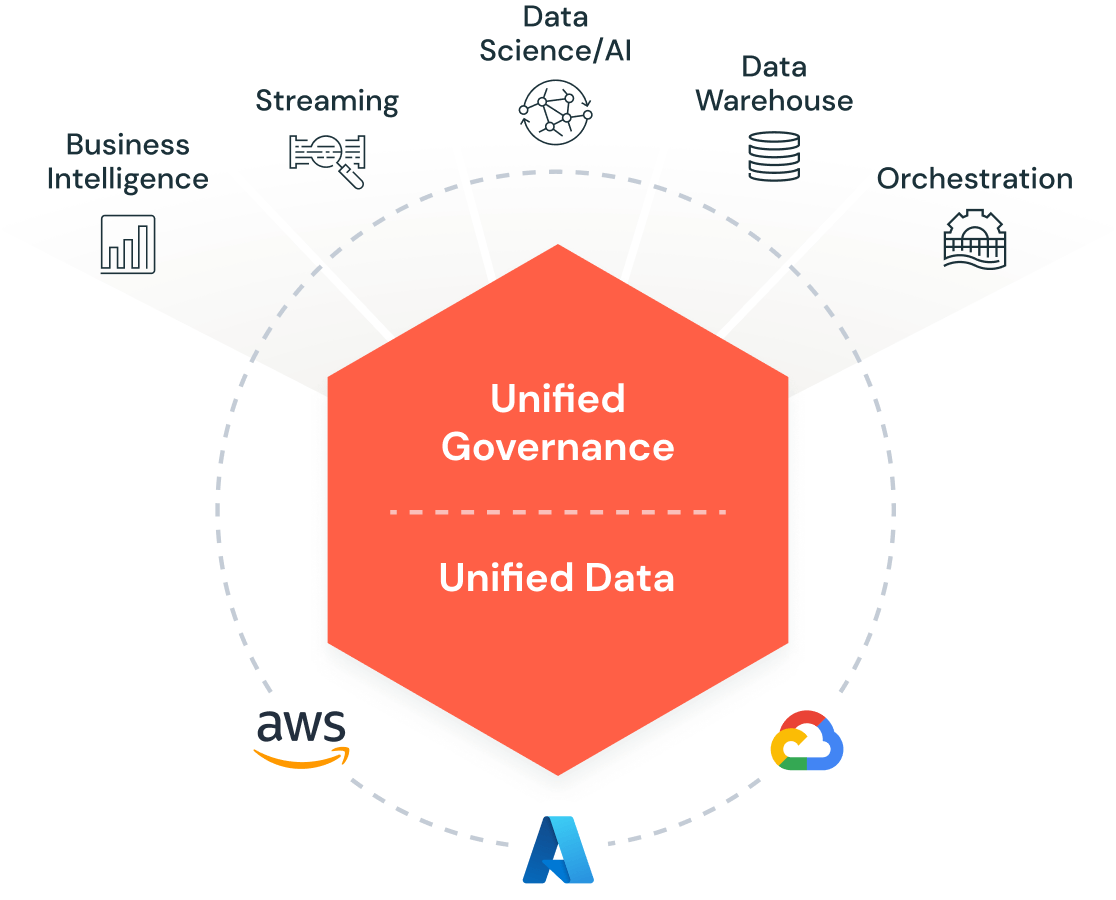
Databricks est disponible en mode cloud managé sur les principales plateformes (AWS, Azure, Google Cloud). Sur Azure par exemple, Azure Databricks est proposé en service natif, intégré à l’écosystème Azure. Cette multi-disponibilité permet à chaque entreprise d’utiliser Databricks sur son environnement cloud favori, avec une expérience très similaire.
L’écosystème Databricks : composants et fonctionnalités clés
Pour comprendre ce que Databricks peut apporter, il faut passer en revue les principaux composants de son écosystème. Databricks fournit en effet un ensemble d’outils et services couvrant tout le processus analytique de bout en bout, de l’ingestion de données jusqu’au déploiement de modèles de machine learning. Les éléments majeurs incluent :
- Workspace collaboratif & Notebooks : L’interface de Databricks se présente sous la forme de workspaces partagés où les utilisateurs peuvent créer des notebooks en Python, SQL, R ou Scala. Ces notebooks permettent d’écrire et d’exécuter du code Spark de façon interactive, de visualiser des résultats, le tout dans un contexte collaboratif en temps réel. Plusieurs personnes peuvent travailler sur un même notebook, ajouter des commentaires, et les notebooks peuvent être versionnés via Git.
- Clusters managés (Apache Spark) : Au cœur de Databricks se trouve Apache Spark, moteur de traitement distribué qui exécute les calculs de big data. Databricks simplifie grandement la gestion des clusters Spark en les rendant managés et auto-adaptatifs. Concrètement, un utilisateur peut créer un cluster en quelques clics sans se soucier de l’infrastructure sous-jacente. Les ressources de calcul allouées (taille du cluster, nombre de nœuds) peuvent s’ajuster automatiquement en fonction de la charge de travail (autoscaling). Les clusters peuvent être paramétrés pour s’éteindre automatiquement en cas d’inactivité, optimisant ainsi les coûts.
- Delta Lake : Delta Lake est le socle technologique du lakehouse Databricks. C’est un format de stockage open source, basé sur des fichiers Parquet, qui apporte une couche transactionnelle ACID par-dessus un data lake traditionnel. Grâce à Delta Lake, les données stockées (sur AWS S3, Azure Data Lake, etc.) bénéficient de propriétés essentielles : transactions ACID (Atomicité, Cohérence, Isolation, Durabilité) sur les modifications de données, historisation des versions de données (time travel), contrôle de schéma, et possibilité de faire des opérations
MERGE/UPDATE/DELETEdirectement dans les data lakes. Par exemple, Delta Lake journalise toutes les modifications apportées aux fichiers dans un journal de transactions, ce qui protège l’intégrité des données et permet de retrouver l’état exact d’un jeu de données à n’importe quel point dans le temps. On peut ainsi facilement corriger une table à une version antérieure ou reproduire une analyse à l’identique, ce qui est précieux pour la traçabilité et la conformité. De plus, Delta Lake unifie les traitements streaming et batch sur la même table : on peut ingérer des flux de données en temps réel tout en permettant des requêtes analytiques SQL sur l’historique, sans distinction. En résumé, Delta Lake apporte au lac de données une fiabilité de niveau entrepôt, résolvant les écueils classiques des data lakes (données corrompues, qualité non maîtrisée, données “perdues” dans un stockage objet). Ouverture vers Apache Iceberg. Historiquement, le lakehouse Databricks reposait sur le format Delta Lake. Depuis le rachat de Tabular (la société fondée par les créateurs d’Apache Iceberg) en 2024, Databricks a fait converger les deux mondes : grâce à Delta Lake UniForm et à Unity Catalog, une même table peut être lue indifféremment comme du Delta ou de l’Iceberg, et Unity Catalog gère désormais nativement des tables Apache Iceberg (fonctionnalité passée en disponibilité générale). C’est un point stratégique : il réduit le verrouillage propriétaire et permet de partager les données avec des moteurs tiers (dont Snowflake), au cœur de la « guerre des formats » de table.
- Databricks SQL & Entreposage de données : La plateforme propose un module Databricks SQL qui permet aux analystes et aux outils de Business Intelligence d’interagir avec le Lakehouse comme avec un entrepôt de données. On peut créer des tables, écrire des requêtes SQL standard sur les données Delta Lake, et même définir des tableaux de bord. Le moteur SQL de Databricks (basé sur Spark SQL avec des optimisations comme Photon pour l’exécution en C++) est conçu pour des performances élevées sur des volumes massifs. Databricks SQL vise ainsi à combiner la souplesse du lac (stockage peu coûteux de toutes les données) et la performance d’un data warehouse pour les requêtes analytiques courantes. Cela ouvre la porte à un usage BI à grande échelle directement sur le lakehouse – par exemple interroger des milliards de lignes de logs ou de ventes avec des outils comme Power BI, sans déplacement de données vers un entrepôt tiers.
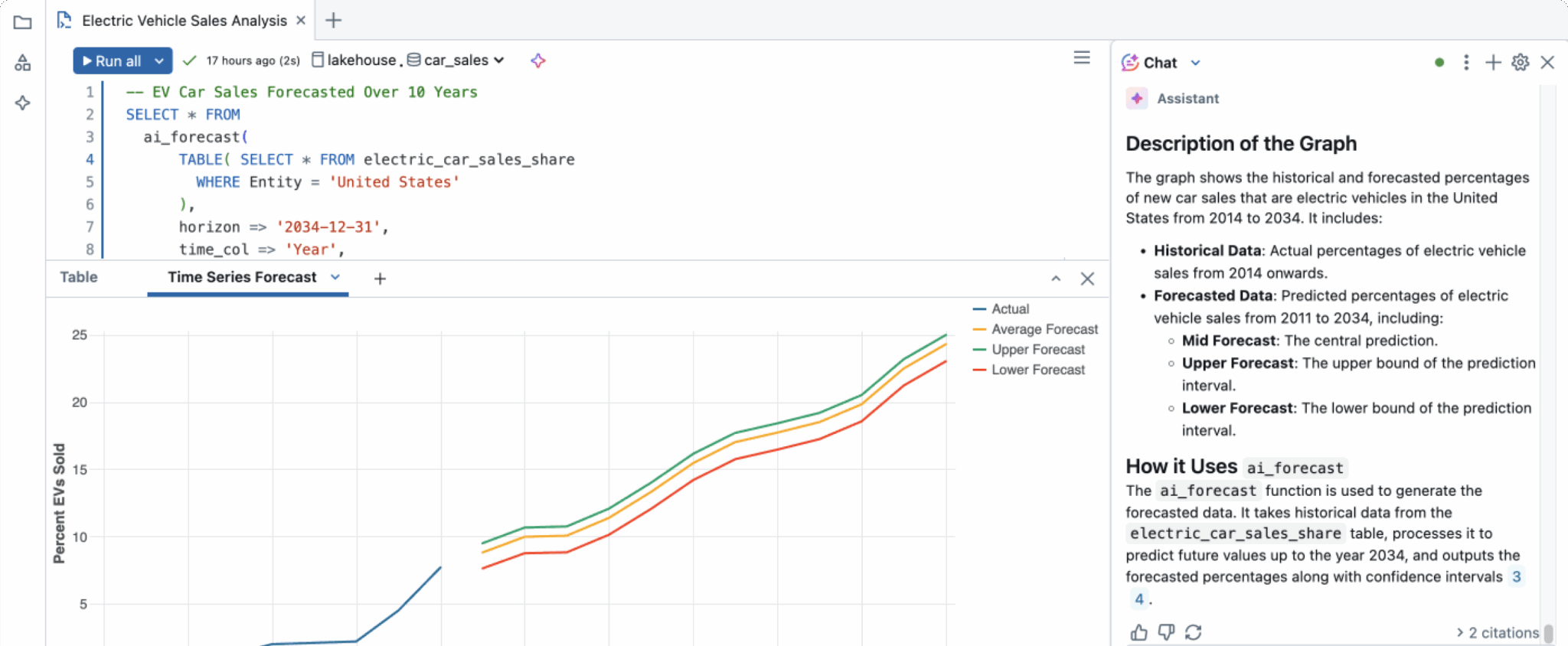
- Job Scheduler et pipelines : Databricks offre des fonctionnalités d’ordonnancement et d’orchestration de tâches. Via l’outil Jobs, on peut planifier l’exécution récurrente de notebooks ou de scripts, pour construire des pipelines de données automatisés. Par exemple, on pourra définir un job qui chaque nuit ingère des fichiers bruts, les transforme avec Spark et les sauvegarde en Delta Lake optimisé. L’ordonnanceur permet de chaîner des tâches dépendantes (notebook Spark, requête SQL, script Python, etc.) pour former des workflows complets. Databricks propose aussi Lakeflow Declarative Pipelines (anciennement Delta Live Tables) permettant de définir des pipelines ETL en déclaratif (avec gestion des dépendances et qualité de données intégrée). Enfin, la plateforme s’interface bien avec des orchestrateurs externes comme Apache Airflow pour ceux qui ont déjà cette brique dans leur SI. En somme, toute la chaîne de traitement de données peut être gérée au sein de Databricks, de l’ingestion à l’alimentation de tableaux de bord, en passant par le machine learning.
- Unity Catalog (gouvernance) : À mesure que l’usage de Databricks se développe dans une entreprise, la question de la gouvernance et de la sécurité des données devient cruciale. Unity Catalog est la couche de gestion des méta-données et des droits d’accès dans l’écosystème Databricks. Il centralise l’inventaire de tous les actifs data de la plateforme – tables Delta, fichiers, features de ML, dashboards – et permet de définir des contrôles d’accès fins (par utilisateur, rôle, groupes) de manière cohérente sur l’ensemble. Unity Catalog fournit aussi un catalogue de données avec recherche, et tient à jour l’historique des lignées de données (data lineage) pour tracer l’origine et l’usage des données. Cette couche unifiée facilite le respect des normes de sécurité et de conformité (par ex. GDPR) en garantissant que seules les personnes autorisées accèdent aux données sensibles, et en offrant de la visibilité sur qui utilise quoi.
- MLflow (MLOps & GenAI) : Databricks s’intègre nativement avec MLflow, l’outil open source qu’il a initié pour gérer le cycle de vie des modèles. MLflow trace les expériences (paramètres, métriques, artefacts), compare les runs et reproduit un entraînement à l’identique. Nouveauté 2025 : avec MLflow 3.0, l’outil a été repensé pour l’IA générative — suivi (tracing) des appels de LLM, gestion des prompts, évaluation assistée par LLM et observabilité d’agents, y compris déployés hors de Databricks. Côté gouvernance des modèles, Databricks recommande désormais de gérer les modèles dans Unity Catalog (avec un système d’alias comme
@champion/@challenger) plutôt que via les anciens stages Staging/Production du Model Registry, en voie d’obsolescence. Un modèle validé peut ensuite être déployé via Mosaic AI Model Serving.
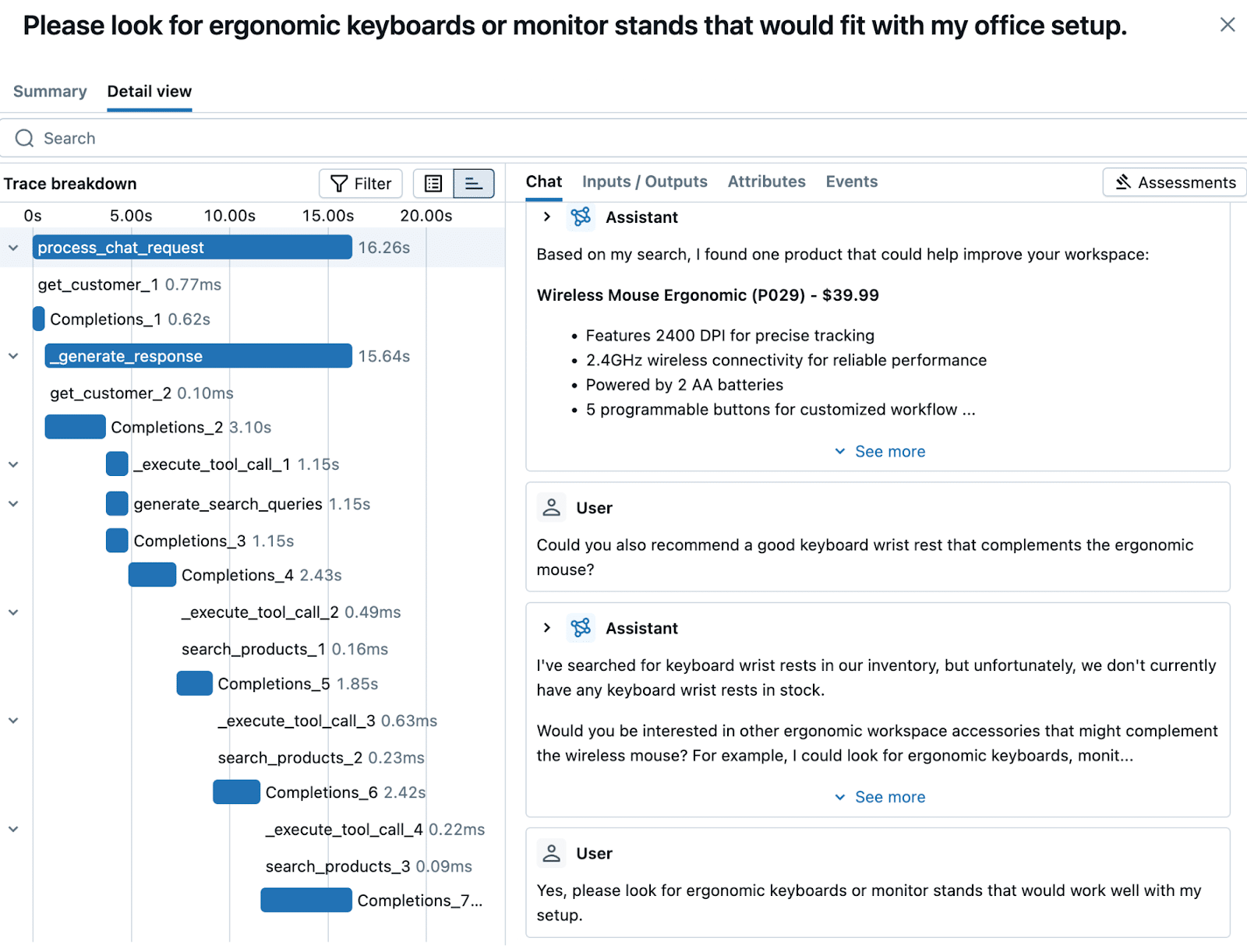
Grâce à cet écosystème riche, Databricks permet aux entreprises d’améliorer leurs processus analytiques et de faciliter la collaboration entre les équipes data (data engineers, data scientists, analystes métier). La promesse est de briser les silos traditionnels : chacun peut travailler sur la même plateforme avec un langage commun (les données), tout en disposant des outils adaptés à son métier.
Mosaic AI : le volet intelligence artificielle générative
Depuis le rachat de MosaicML (2023), Databricks a regroupé ses capacités d’IA sous la marque Mosaic AI, désormais au cœur de la plateforme. Pour une entreprise, cela ouvre la voie à des cas d’usage GenAI directement sur ses données gouvernées, sans les déplacer :
- Mosaic AI Model Serving : déploiement unifié de modèles (ML classique, LLM open source ou propriétaires) derrière une API, avec mise à l’échelle automatique.
- Mosaic AI Vector Search : base vectorielle managée, synchronisée avec vos tables, socle des applications de RAG (retrieval-augmented generation).
- Agent Bricks / Agent Framework : pour construire, évaluer et déployer des agents IA ancrés dans vos données d’entreprise, avec support du protocole MCP et gouvernance via Unity Catalog.
- AI Functions : appeler un LLM directement en SQL (
ai_query,ai_classify,ai_parse_document…) pour enrichir ou classifier des données à grande échelle. - AI/BI Genie : interroger ses données en langage naturel (« quelles sont mes ventes par région ce trimestre ? ») et générer des tableaux de bord, sans écrire de SQL.
- Databricks Assistant : un copilote intégré qui aide à écrire du code, des requêtes et des pipelines, et à déboguer.
Le tout est régi par Unity Catalog (mêmes permissions, même traçabilité que les données), ce qui distingue l’approche de Databricks : la gouvernance s’applique de la donnée jusqu’aux modèles et aux agents.
Databricks en action : cas d’usage concrets
Maintenant que nous avons vu les composants, quelles applications concrètes une entreprise peut-elle faire de Databricks ? Les cas d’usage sont variés et couvrent l’ensemble du spectre analytique. En voici quelques exemples typiques :
- Entrepôt de données & Business Intelligence : Databricks peut servir de plateforme de Data Warehouse scalable. Grâce à Databricks SQL, les analystes peuvent interroger de larges volumes de données en SQL, créer des vues agrégées et alimenter des tableaux de bord BI. Par exemple, une chaîne de distribution peut centraliser ses données de ventes quotidiennes dans Delta Lake et permettre aux équipes BI d’y exécuter des requêtes SQL pour le reporting financier ou le suivi des KPI, même sur des années d’historique. La puissance de calcul distribuée assure des temps de réponse acceptables, et la qualité des données est garantie par Delta (schémas cohérents, données à jour). En combinant data lake et data warehouse sur une même plateforme, on évite les doublons et délais de copie de données, ce qui permet un reporting plus flexible et rapide sur l’ensemble des données de l’entreprise.
- Ingénierie des données & pipelines ELT/ETL : Databricks excelle dans le traitement de gros volumes de données pour l’alimentation des différents systèmes. Un cas d’usage courant est la construction de pipelines d’ingestion et transformation des données brutes. Par exemple, une entreprise peut recevoir chaque jour des fichiers logs ou des données externes (CSV, JSON…). Un notebook Databricks peut être programmé pour les charger (depuis AWS S3, Azure Blob ou autres), les nettoyer et les transformer en tables Delta prêtes pour l’analyse. Grâce à la puissance de Spark, des opérations lourdes (jointures sur des milliards de lignes, agrégations complexes, enrichissement par des référentiels) sont réalisées en quelques minutes là où un script SQL traditionnel aurait mis des heures. Le tout peut être orchestré via les Jobs pour tourner automatiquement. Databricks permet ainsi d’industrialiser vos flux de données : par exemple alimenter quotidiennement une table client 360° consolidée à partir de multiples sources (CRM, web analytics, etc.). Ce cas d’usage data engineering est fréquent dans les industries voulant moderniser leur data pipeline existant, en migrant d’anciens ETL vers le Lakehouse. Le gain se mesure en simplicité (un seul environnement) et en temps de traitement réduit.
- Streaming temps réel et IoT : Grâce à Spark Structured Streaming et Delta Lake, Databricks gère aussi des cas d’usage en temps réel. Par exemple, dans le domaine industriel ou IoT, des capteurs peuvent envoyer en continu des données (mesures, événements) qui sont ingérées en streaming dans Databricks. Un cluster Spark peut consommer des flux Kafka ou Azure Event Hub, appliquer à la volée des transformations ou détections d’anomalies, puis écrire ces données quasi en temps réel dans Delta Lake. On peut alors combiner les analyses historique et temps réel. Concrètement, ceci ouvre la voie à des applications comme la maintenance prédictive (analyser en temps réel les données de capteurs pour détecter une dérive et anticiper une panne) ou l’optimisation de chaîne logistique (suivi des stocks et des expéditions en direct). Databricks sert de hub pour corréler ces données streaming avec d’autres données entreprise (par ex. données historiques de pannes, données météo, etc.) afin de produire des tableaux de bord en temps quasi-réel ou d’entraîner des modèles prédictifs continuellement mis à jour. De plus, l’intégration de Databricks avec des plateformes de streaming comme Confluent Kafka permet d’insérer la plateforme dans une architecture évènementielle plus large, où les données des systèmes opérationnels (ERP, CRM…) sont diffusées en temps réel vers Databricks pour enrichissement analytique. Les décisions ne se font plus à J+1 mais en temps réel, ce qui est un avantage compétitif notable dans beaucoup de secteurs.
- Data Science & Machine Learning collaboratif : Databricks est très prisé des équipes de data science pour mener des projets de machine learning de bout en bout. Un scénario concret : une équipe souhaite développer un modèle de prédiction de churn clients. Les data scientists vont explorer les données clients (profil, transactions, interactions support…) dans un notebook partagé, en utilisant PySpark ou Pandas API on Spark pour manipuler les données directement là où elles résident (dans le lakehouse). Ils peuvent tester divers features et algorithmes ML, et suivre leurs expérimentations grâce à MLflow (chaque essai entraîné est enregistré avec ses métriques). Une fois un modèle satisfaisant obtenu, il peut être enregistré dans le Model Registry de MLflow. De là, les ingénieurs peuvent le déployer en production sur Databricks (par exemple via un job quotidien qui score les nouveaux clients, ou via l’API REST Databricks pour servir le modèle en temps réel). Toute cette collaboration se fait sans couture sur la même plateforme – les données brutes sont accessibles, les transformations partagées, et les résultats comparés aisément. Ce workflow évite les frictions habituelles (silos entre data engineers qui préparent les données et data scientists qui les consomment). Il facilite aussi le passage à l’échelle : si l’échantillon initial de modélisation doit être étendu à l’ensemble des données, il suffit d’augmenter la taille du cluster et de relancer le notebook, sans avoir à refondre le code. Databricks est utilisé pour des applications ML variées : détection de fraude bancaire, recommandation de produits en e-commerce, scoring de risques en assurance, analyse d’images médicales… toute problématique nécessitant de la donnée massive et du calcul distribué pour entraîner les modèles. Avec Databricks, on peut entraîner sur des téraoctets de données en exploitant des bibliothèques comme Spark MLlib, TensorFlow ou PyTorch (ces dernières s’appuyant sur les clusters GPU du cloud via Databricks). La plateforme prend en charge l’ensemble du cycle de vie ML, depuis la préparation des données jusqu’au suivi post-déploiement (monitoring des performances via MLflow). C’est pourquoi Databricks est parfois considérée comme l’une des meilleures solutions pour le MLOps en entreprise.
Bien sûr, cette liste de cas d’usage n’est pas exhaustive. Databricks est, par essence, une plateforme généraliste pour traiter de la donnée, et on la retrouve dans des domaines aussi variés que la finance (analyse de risques, détection d’anomalies financières), la santé (analytique génomique, prédiction d’épidémies), les télécoms (optimisation de réseaux), ou le jeu vidéo (analyses comportementales de joueurs). Son positionnement multiservices la rend utile partout où il y a des données volumineuses et hétérogènes à exploiter et où l’on cherche à faire travailler ensemble divers profils techniques sur des projets data.
Intégration de Databricks dans le SI d’entreprise
L’adoption de Databricks ne se fait pas en vase clos : il est essentiel qu’elle s’intègre harmonieusement dans votre système d’information et votre écosystème technologique existant. Heureusement, la plateforme a été conçue pour être ouverte et interopérable avec de nombreux outils et standards du marché.
Intégration multi-cloud et on-premise : Databricks est un service cloud, mais il peut se connecter à vos données où qu’elles se trouvent. Par exemple, vous pouvez lire/écrire des données depuis et vers vos bases de données existantes (SQL Server, Oracle…), des data lakes (Amazon S3, Azure Data Lake, Google Cloud Storage) ou des data warehouses traditionnels. Des connecteurs Spark sont disponibles pour à peu près toute source de données (JDBC/ODBC pour bases SQL, connecteurs spécialisés pour MongoDB, Elastic, etc.). Il est également possible d’utiliser Databricks Connect, un client qui permet d’exécuter du code Spark depuis un IDE local (PyCharm, VS Code…) sur un cluster Databricks distant – pratique pour les développeurs qui veulent garder leur environnement favori tout en profitant de la puissance du cluster. Pour des environnements on-premise plus traditionnels, Databricks ne peut pas être installé dans votre datacenter. En revanche, via des outils comme Delta Sharing, Databricks peut consommer ou exposer des données de/vers des systèmes externes de manière sécurisée, facilitant la collaboration inter-organisations.
Intégration avec les outils de streaming et message queuing : Comme évoqué, Databricks s’intègre particulièrement bien avec Apache Kafka et son équivalent managé Confluent pour consommer des flux de données en temps réel. De nombreux clients utilisent Kafka comme bus temps réel pour acheminer les événements de leurs applications vers Databricks, où ils sont traités via Spark Streaming. Inversement, on peut utiliser Databricks pour produire des données (par exemple les résultats d’un modèle ML en temps réel) et les envoyer vers des topics Kafka afin d’alimenter d’autres systèmes en aval. Cette architecture log-centric couplant Kafka et Databricks permet de relier le monde opérationnel au monde analytique en temps réel. Databricks supporte également d’autres systèmes de messagerie/pub-sub comme Azure Event Hubs, Google Pub/Sub, Kinesis, etc., élargissant les possibilités d’ingérer des données événementielles variées (logs applicatifs, clics web, données IoT, transactions…).
Collaboration avec les outils BI et applications : Databricks ne remplace pas vos outils de Business Intelligence ou vos applications métiers, il les complète. Grâce à son moteur SQL compatible JDBC/ODBC, les outils BI comme Tableau, Power BI, Qlik ou même Excel peuvent se connecter à Databricks SQL et interroger les données du lakehouse en live. Cela signifie que vos utilisateurs métier peuvent continuer d’utiliser leurs tableaux de bord favoris, tout en bénéficiant de la fraîcheur et de la profondeur des données traitées par Databricks en arrière-plan. Databricks devient ainsi une sorte de backend analytique hautement scalable pour alimenter vos applications. On voit également des intégrations avec des applications métiers spécifiques : par exemple, SAP a noué un partenariat avec Databricks pour permettre d’analyser des données SAP conjointement avec d’autres sources dans le lakehouse. Via des connecteurs et API, Databricks s’insère donc dans les processus existants sans tout révolutionner côté utilisateur final.
DevOps, CI/CD et gouvernance : Intégrer Databricks, c’est aussi l’intégrer dans vos processus de développement et de gouvernance. Il est recommandé de gérer vos notebooks et code Databricks sous Git (Databricks propose une intégration Git native) pour appliquer vos pratiques de versioning et revue de code. Des outils en ligne de commande et API REST permettent d’automatiser le déploiement de notebooks, de jobs, de configurations clusters – on peut ainsi inclure Databricks dans des pipelines CI/CD (par ex. avec Azure DevOps, GitHub Actions, Jenkins…). Côté sécurité, Databricks s’intègre avec les annuaires d’entreprise (Azure AD, AWS IAM…) pour la gestion des identités et accès. La comptabilisation des coûts peut être suivie via les outils cloud standards (par ex. Cost Management d’Azure), sachant que Databricks offre aussi son propre monitoring des unités de consommation. En résumé, il est tout à fait possible d’utiliser Databricks dans un cadre industriel maîtrisé, intégré à vos workflows de développement et vos politiques IT existantes.
Enfin, soulignons l’écosystème de partenaires technologiques autour de Databricks. De nombreux éditeurs proposent des connecteurs ou intégrations avec Databricks (par exemple, des outils ETL comme Fivetran, Talend ou Informatica peuvent charger des données directement dans Delta Lake). Databricks lui-même propose une place de marché de solutions partenaires (data ingestion, data quality, catalogues…). Cet écosystème en expansion fait de Databricks un élément de plus en plus standard dans l’architecture data moderne, capable de communiquer avec les autres briques de votre système d’information.
Conseils d’adoption et points d’attention
Comme toute technologie puissante, Databricks doit être adopté de manière réfléchie pour en tirer le meilleur parti. Voici quelques conseils et points d’attention pour une utilisation réussie en entreprise :
- Montez en compétence progressivement : Databricks offre une multitude d’outils et de possibilités, ce qui peut rendre sa prise en main initiale délicate pour les nouveaux utilisateurs. La plateforme peut sembler « riche mais complexe » de prime abord. Il est conseillé de commencer par des cas d’usage ciblés et de bien former les équipes (via les formations officielles ou partenaires comme stat4decision, qui propose par exemple une formation dédiée). L’interface notebook et les concepts Spark peuvent nécessiter un changement d’habitudes, surtout pour des analystes peu familiers du code. De plus, Databricks n’est pas un outil no-code : une certaine appétence pour la programmation (Python/SQL) est nécessaire pour en exploiter le potentiel, ce qui peut requérir un accompagnement des profils moins techniques.
- Maîtrisez les coûts cloud : Étant une solution managée sur le cloud, Databricks implique un coût qui peut devenir significatif si les ressources ne sont pas contrôlées. Le modèle de facturation repose généralement sur l’usage (par exemple des DBU – Databricks Units – consommés en fonction du type de machines et du temps d’utilisation). Cela signifie que si un cluster tourne 24h/24 inutilement, la facture grimpera. Il est essentiel de configurer les clusters avec auto-termination (arrêt automatique) en cas d’inactivité, d’utiliser l’autoscaling pour ajuster la taille aux besoins, et de suivre de près la consommation. Par rapport à un déploiement Spark open source sur vos propres serveurs, Databricks apporte de nettes simplifications mais à un prix premium. Certaines petites structures ou projets limités pourront le trouver onéreux si l’usage n’est pas optimisé. La bonne nouvelle est que la facturation à l’usage incite justement à optimiser : en formant vos équipes aux bonnes pratiques (ex. éviter de stocker trop de données sur le cluster, arrêter les jobs aussitôt finis, utiliser les bons types d’instances), vous pouvez minimiser le coût par workload et ainsi bénéficier des avantages sans explosion budgétaire. N’hésitez pas à tirer parti des outils de monitoring de Databricks et du cloud pour identifier les goulots d’étranglement et opportunités d’optimisation.
- Sécurité et gouvernance dès le départ : Intégrer Databricks dans une entreprise signifie y stocker potentiellement des données sensibles. Il est donc primordial d’activer Unity Catalog et de définir clairement les rôles et permissions : qui peut voir/modifier quelles données, qui peut démarrer des clusters, etc. Databricks permet de connecter l’authentification aux identities de l’entreprise (SSO) – ce qui devrait être mis en place pour éviter la multiplication de comptes. Pensez également à chiffrer les données au repos (les cloud providers et Delta Lake le supportent généralement de manière transparente) et en transit. Côté gouvernance, impliquez dès le début vos équipes de sécurité et d’architecture pour valider l’usage (par exemple, s’assurer que le déploiement de Databricks respecte les contraintes réglementaires, notamment si des données doivent rester dans certaines régions). L’audit logging de Databricks peut être activé pour tracer toutes les opérations et accès – une bonne pratique en contexte entreprise.
- Choisissez les bons cas d’usage : Databricks brille particulièrement pour certains types de charges : traitements batch ou stream sur très gros volumes, besoins variés (SQL + ML dans le même flow), projets nécessitant collaboration étroite entre data engineers et data scientists. En revanche, pour de simples analyses BI sur données limitées, un entrepôt cloud classique ou un outil de visualisation seul peuvent suffire sans la complexité de Spark. De même, si votre cas d’usage ML n’implique que quelques centaines de milliers de lignes, un environnement plus léger peut parfois faire l’affaire. Utilisez donc Databricks là où sa valeur ajoutée est la plus forte : lorsque la scale (volume, vélocité) ou la convergence des usages requiert une plateforme robuste. Pour d’autres besoins, il peut coexister avec des solutions complémentaires (par exemple, certaines entreprises utilisent à la fois Databricks et un data warehouse comme Snowflake : Databricks pour les travaux data science/ingénierie, Snowflake pour les tableaux de bord BI classiques). L’important est d’architecturer chaque composant selon ses forces.
En résumé, une adoption réussie de Databricks passe par une montée en compétence progressive, une gouvernance maîtrisée, et une optimisation continue des usages et coûts. Le soutien de la direction (pour investir dans la plateforme et la formation) et la création d’une communauté interne d’utilisateurs Databricks peuvent accélérer l’apprentissage collectif. N’oublions pas que derrière Databricks existe aussi une communauté d’experts et de praticiens (bien que plus restreinte que pour des projets 100% open source) – vous pourrez trouver du support via les forums officiels ou des meetups, et bien sûr auprès du support Databricks qui est reconnu pour sa réactivité.
Et par rapport à ses concurrents ?
Face à Databricks, plusieurs acteurs majeurs se positionnent. Snowflake reste très fort sur le data warehousing et le partage de données ; il a toutefois comblé une partie de son retard côté data science et IA (Snowpark, Cortex AI) et adopté Apache Iceberg via son catalogue Polaris. Microsoft Fabric est devenu la plateforme analytique unifiée phare de Microsoft, bâtie autour de OneLake – elle remplace progressivement Azure Synapse Analytics (que l’article citait) et s’intègre étroitement à Power BI et à l’écosystème Microsoft. Côté AWS, Amazon SageMaker s’est élargi en une plateforme unifiée (la nouvelle génération de SageMaker rapproche données et ML, dans une logique proche du lakehouse). Google BigQuery reste un entrepôt serverless très performant, complété par Vertex AI pour le ML. Enfin, signe de la centralité de Databricks, SAP l’a directement intégré : SAP Business Data Cloud (lancé début 2025) embarque un « SAP Databricks » managé, relié par Delta Sharing en zéro-copie pour analyser les données SAP avec leur contexte métier.
L’atout de Databricks demeure sa capacité à réunir sous un même toit, et une même gouvernance (Unity Catalog), le data engineering, le SQL analytique, le streaming, le machine learning et désormais l’IA générative.
Databricks face à Dataiku et KNIME
Databricks se distingue des plateformes telles que Dataiku ou KNIME principalement par sa philosophie d’intégration profonde autour de Spark et son modèle « Lakehouse ». Tandis que Dataiku et KNIME sont des solutions très appréciées pour leur approche visuelle et leur simplicité d’utilisation, particulièrement adaptées aux utilisateurs métier et aux data scientists débutants ou intermédiaires, Databricks est plus orientée vers les profils techniques et les traitements distribués à grande échelle.
Dataiku se démarque par une interface conviviale, un fort accent sur l’automatisation du machine learning (AutoML) et un excellent accompagnement du cycle complet de développement ML, tout en restant plus généraliste que Databricks sur les aspects d’infrastructure big data.
KNIME, quant à elle, offre une plateforme open-source très accessible pour les workflows d’analyse visuelle et le prototypage rapide mais reste moins performante en termes de scalabilité pour les traitements intensifs.
Ainsi, Databricks convient mieux aux entreprises ayant des besoins importants en termes de volume de données et de puissance de calcul distribué, tandis que Dataiku et KNIME répondent souvent mieux aux besoins de rapidité, de simplicité et de démocratisation des projets data science à plus petite échelle.
Conclusion
Databricks s’affirme aujourd’hui comme une plateforme de choix pour construire des architectures data et IA unifiées en entreprise. En embrassant le paradigme du Lakehouse, elle permet de combiner, au sein d’un même environnement collaboratif, les workloads autrefois dissociés du data warehousing, du big data et du machine learning. Avec des composants tels que Delta Lake pour la fiabilité des données, MLflow pour le suivi des modèles, et un workspace collaboratif propice à la productivité, Databricks offre aux équipes une boîte à outils complète pour innover à partir des données.
Les bénéfices d’une telle plateforme se font sentir à plusieurs niveaux : accélération des projets data/IA (moins de temps perdu en configurations et transferts de données), meilleure collaboration entre profils techniques et métier, démocratisation de l’accès à l’analytique avancée, et souvent amélioration de la performance des traitements sur les grands volumes. De plus, l’approche cloud managée de Databricks apporte une agilité précieuse – il est facile de débuter un projet sur un petit cluster et d’étendre la puissance de calcul en fonction de la croissance des données ou de l’ambition des analyses, sans refonte d’infrastructure.
Pour autant, il convient de garder à l’esprit qu’aucune solution n’est magique. Databricks requiert un investissement humain (formation aux concepts Spark, à l’optimisation des jobs, etc.) et financier (coût du service managé) qu’il faut anticiper. Le succès de son utilisation en entreprise dépendra de la capacité à identifier les bons cas d’usage où son apport est décisif, à accompagner le changement auprès des équipes, et à instituer les bonnes pratiques (tantôt techniques, tantôt de gouvernance).
En définitive, si votre organisation cherche à exploiter au mieux des données toujours plus volumineuses et variées, à faire collaborer efficacement data engineers, data scientists et analystes, et à mettre en production des solutions data/IA de manière industrielle, Databricks constitue une option solide à envisager. Sans être une potion miracle, cette plateforme a démontré sa capacité à “guide[r] les décisions business stratégiques” dans des entreprises de tous secteurs, des géants du pétrole aux maisons de couture en passant par les acteurs de la tech. Adopter Databricks, c’est en quelque sorte doter son entreprise d’un moteur unifié pour la donnée et l’IA, moteur qui, bien piloté, peut accélérer la transformation data-driven et offrir un avantage concurrentiel dans la donnée.
En explorant l’écosystème Databricks de manière pragmatique et éclairée – comme nous l’avons fait dans cet article – vous serez mieux armés pour décider comment mettre le Lakehouse à profit pour vos propres défis métiers. Nous espérons que ce tour d’horizon vous aura éclairé sur l’usage de Databricks en entreprise, et vous aura donné envie d’expérimenter par vous-même cette plateforme au carrefour de la data et de l’IA. Bonne exploration du Lakehouse !
Maîtrisez Databricks avec Stat4decision
Vous souhaitez exploiter pleinement le potentiel de Databricks dans votre organisation ? Stat4decision vous accompagne dans votre montée en compétences avec des formations spécialisées et un accompagnement personnalisé.
Nos Formations Databricks & Infrastructure Data
Formation Databricks pour Utilisateurs (3 jours) Découvrez comment exploiter la plateforme Databricks de A à Z : de la prise en main des notebooks collaboratifs à l’orchestration de pipelines complexes, en passant par l’optimisation des performances avec Delta Lake et l’intégration MLflow pour vos projets de machine learning.
Formations Data Engineering & Infrastructure
- Data Lake & Architecture Lakehouse : Concevez et implémentez des architectures data robustes
- Pipeline de données : Automatisation et orchestration avec Apache Airflow
- DevOps pour la Data : Git, CI/CD et bonnes pratiques pour l’industrialisation
- Cloud Data Solutions : AWS, Azure, GCP pour vos projets data
Pourquoi Choisir Stat4Decision ?
Expertise Reconnue
Nos formateurs sont des praticiens expérimentés qui maîtrisent les enjeux réels de déploiement et d’optimisation des infrastructures data.
Approche Pratique
Formations basées sur des cas d’usage concrets avec manipulation d’environnements Databricks réels et projets guidés.
Accompagnement Personnalisé
Petits groupes (max 8 participants), suivi post-formation et conseils adaptés à vos problématiques métier.
Modalités Flexibles
- Sessions inter-entreprises à Paris ou à distance
- Formations intra-entreprise sur mesure
- Financement OPCO avec notre certification Qualiopi
Services d’Accompagnement
Au-delà de la formation, nous proposons :
- Audit de votre architecture data actuelle
- Conseil en stratégie d’implémentation Databricks
- Accompagnement à la migration vers le cloud
- Support technique pour vos premiers projets
Contactez-nous
Partager cet article