
Introduction
Le traitement de données massives avec Apache Spark via l’API PySpark est devenu incontournable dans les architectures big data modernes. Cependant, malgré la puissance annoncée de Spark, de nombreux projets peinent à obtenir des performances satisfaisantes en production. La raison ? Une méconnaissance du fonctionnement interne de Spark, des erreurs de configuration, ou encore l’usage de mauvaises pratiques lors de l’écriture de code.
Cet article propose un guide complet pour améliorer l’efficacité de vos traitements PySpark. Il s’adresse à un public technique — data engineers, data scientists avancés ou développeurs big data — souhaitant passer à l’échelle sur des jeux de données volumineux, sans compromettre la stabilité ni exploser la consommation de ressources.
1. Comprendre le modèle d’exécution de Spark
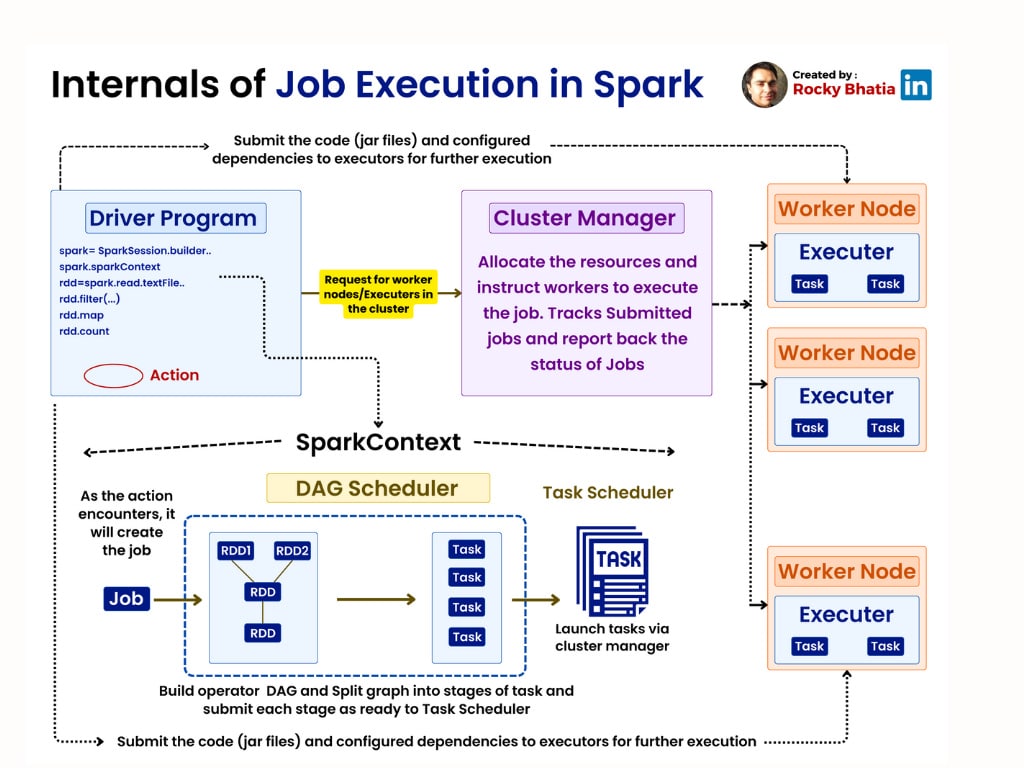
Avant de chercher à optimiser un pipeline PySpark, il est crucial de comprendre comment Spark exécute une requête. Spark repose sur le principe de l’évaluation paresseuse (lazy evaluation), ce qui signifie que les transformations (comme .filter() ou .select()) sont enregistrées mais non exécutées tant qu’une action (comme .collect() ou .show()) n’a pas été appelée.
Lorsqu’une action est déclenchée, Spark construit un DAG (Directed Acyclic Graph) d’opérations, qu’il décompose ensuite en stages parallélisables, eux-mêmes composés de tasks réparties sur les différents nœuds du cluster.
Le choix de l’API est également important : les DataFrames sont à privilégier par rapport aux RDDs car ils bénéficient de l’optimiseur Catalyst, capable de réécrire le plan logique d’exécution pour le rendre plus performant.
Exemple :
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Demo").getOrCreate()
df = spark.read.parquet("/data/clients")
result = df.filter("age > 30").groupBy("region").count()
result.show()
Ce traitement ne déclenche aucune exécution tant que .show() n’est pas appelé. Catalyst interviendra pour optimiser le filtre et le groupBy.
2. Configurer correctement votre session Spark
La performance d’un job Spark dépend fortement de la manière dont les ressources sont allouées. Une mauvaise configuration des exécuteurs, du driver ou de la mémoire peut conduire à des lenteurs, voire à des erreurs (OOM, shuffle bloqué, etc.).
Voici un exemple de configuration typique :
spark = SparkSession.builder \
.appName("Optimisation") \
.config("spark.executor.memory", "4g") \
.config("spark.executor.instances", "4") \
.config("spark.executor.cores", "2") \
.config("spark.driver.memory", "2g") \
.getOrCreate()
Quelques conseils :
- N’allouez pas trop de mémoire par exécuteur : cela peut réduire la parallélisation.
- Ajustez le nombre d’exécuteurs à la taille réelle de votre cluster.
- Activez l’allocation dynamique si la charge de travail varie :
.config("spark.dynamicAllocation.enabled", "true")
3. Gérer les partitions intelligemment
Spark découpe automatiquement les données en partitions. Mais une mauvaise stratégie peut entraîner un sous-emploi des ressources (trop peu de partitions) ou au contraire une surcharge mémoire (trop de partitions).
La règle empirique est de viser des partitions de 100 à 200 Mo. Pour les ajuster :
# Pour augmenter le parallélisme
repartitioned_df = df.repartition(100)
# Pour réduire le nombre de partitions après un filtre
coalesced_df = df.filter("status = 'actif'").coalesce(10)
Pensez également à surveiller le format des données en entrée. Les petits fichiers CSV ralentissent les lectures ; préférez des formats colonnes compressés comme Parquet ou ORC.
4. Réduire les opérations coûteuses
Certaines opérations PySpark sont très gourmandes, notamment :
.collect(), qui rapatrie toutes les données sur le driver..withColumn()dans une boucle, qui peut dégrader fortement les performances.- L’usage excessif de UDFs Python, qui désactivent Catalyst et ne sont pas optimisés.
Mieux vaut utiliser les fonctions intégrées de PySpark :
from pyspark.sql.functions import col, when, broadcast
# Préférer select à withColumn pour les manipulations simples
cleaned_df = df.select(
col("nom"),
when(col("age") > 18, "majeur").otherwise("mineur").alias("statut")
)
# Utiliser le broadcast pour les petites dimensions
small_df = spark.read.csv("/data/codes.csv")
df = df.join(broadcast(small_df), "code")
5. Caching et persistance raisonnée
Dans certains cas, il est judicieux de cacher un DataFrame si celui-ci est réutilisé plusieurs fois dans le pipeline. Cela permet d’éviter de recalculer les transformations.
filtered = df.filter("type = 'premium'")
filtered.cache()
filtered.groupBy("region").count().show()
filtered.select("client_id", "score").write.parquet("/out")
Attention toutefois : un usage abusif du cache peut saturer la mémoire. N’oubliez pas d’utiliser unpersist() si le DataFrame n’est plus utile.
6. Monitorer et diagnostiquer avec Spark UI
L’interface Spark (généralement accessible sur http://<driver>:4040) fournit des informations essentielles pour détecter les goulots d’étranglement :
- Durée des stages et des tasks
- Utilisation mémoire et CPU
- Volume de shuffle
- Partition skew (déséquilibre entre partitions)
Exemple : un join entre deux DataFrames avec une clé très déséquilibrée entraînera un skew, où une seule tâche prendra beaucoup plus de temps. Une solution peut être de faire du salting sur la clé.
7. Exploiter les outils Spark pour debugger
Pour inspecter le plan d’exécution, utilisez :
df.explain(True)
Cela vous permettra d’identifier les shuffles inutiles, les scans de fichiers, et de vérifier si le broadcast a bien été appliqué. Combinez cette analyse avec des métriques issues du Spark History Server ou d’un outil comme Ganglia ou Prometheus pour monitorer sur le long terme.
8. Bonnes pratiques supplémentaires
- Adoptez des scripts reproductibles, versionnés avec Git.
- Évitez les configurations par défaut (notamment
spark.sql.shuffle.partitions = 200). - Favorisez les tests unitaires de vos transformations avec
pytest+pyspark.sql.testing. - Automatisez les déploiements avec des pipelines CI/CD.
Aller plus loin avec Spark :
Conclusion
PySpark est un outil puissant, mais son bon usage nécessite une compréhension fine du moteur Spark, ainsi qu’une discipline de développement robuste. Les performances ne dépendent pas uniquement de la puissance du cluster, mais aussi de la qualité du code, de la stratégie de partitionnement et de l’architecture du pipeline.
Chez Stat4Decision, nous accompagnons les équipes data dans l’optimisation de leurs flux Spark : audit de performances, montée en compétence sur PySpark et mise en place de bonnes pratiques DevOps data.
Vous souhaitez accélérer vos traitements PySpark et sécuriser vos projets big data ? Écrivez-nous à info@stat4decision.com ou découvrez nos formations Spark dédiées aux architectures distribuées.
Partager cet article