
Depuis plusieurs années, nous intervenons chez des organisations qui disposent déjà d’un entrepôt de données, d’outils d’ingestion modernes, parfois même d’une équipe data structurée. Pourtant, le même constat revient presque systématiquement : les transformations analytiques sont difficiles à comprendre, difficiles à faire évoluer et encore plus difficiles à auditer.
Les tables finales existent. Les dashboards fonctionnent. Mais lorsqu’il faut modifier une règle métier, comprendre l’impact d’un changement ou industrialiser correctement les développements, la fragilité de l’architecture apparaît.
C’est précisément dans ce contexte que dbt s’est imposé comme un standard incontournable.
DBT n’est pas simplement un outil supplémentaire dans la stack. C’est un changement de paradigme : traiter la transformation analytique comme un projet logiciel.
Dans cet article, nous allons détailler ce que cela signifie concrètement, en nous appuyant sur un cas réel inspiré de notre projet pédagogique formation_dbt, que nous utilisons pour former et accompagner des équipes data sur des environnements industrialisés avec GitLab.
Le problème : des transformations SQL sans gouvernance
Dans de nombreuses organisations, les transformations sont écrites directement dans :
- des jobs orchestrés,
- des scripts Python exécutant du SQL,
- des procédures stockées,
- ou des outils ETL historiques.
Le SQL existe déjà. Il est même souvent central. Mais il est dispersé, non versionné proprement, peu documenté, rarement testé.
On observe alors plusieurs symptômes :
- Les dépendances entre tables sont implicites.
- Les transformations intermédiaires sont mal identifiées.
- La logique métier est difficile à localiser.
- Les modifications génèrent des effets de bord imprévus.
- La documentation est inexistante ou obsolète.
Ce n’est pas un problème technique au sens strict. C’est un problème d’ingénierie.
DBT : transformer comme un logiciel
DBT repose sur une idée extrêmement simple : écrire les transformations en SQL, mais les organiser comme du code logiciel.
Dans un projet dbt, chaque transformation devient un modèle SQL isolé, versionné dans Git, relié explicitement à ses dépendances.
Prenons un exemple simple issu d’un cas typique du projet formation_dbt. Imaginons que nous disposions de deux tables brutes :
- raw_contracts
- raw_claims
L’objectif métier consiste à produire une table consolidée permettant d’analyser la sinistralité par contrat.
Plutôt que d’écrire une requête massive directement en production, nous structurons le projet.
Dans le dossier models/staging, nous nettoyons les données :
-- models/staging/stg_contracts.sql
select
contract_id,
policyholder_id,
cast(start_date as date) as start_date,
cast(end_date as date) as end_date,
status
from {{ source('raw', 'contracts') }}
Le mot clé source() formalise que nous partons d’une table brute déclarée dans la configuration.
Puis dans models/intermediate, nous appliquons la logique métier intermédiaire :
-- models/intermediate/int_claims_enriched.sql
select
c.contract_id,
c.policyholder_id,
cl.claim_id,
cl.claim_amount,
cl.claim_date
from {{ ref('stg_contracts') }} c
join {{ ref('stg_claims') }} cl
on c.contract_id = cl.contract_id
where c.status = 'active'
Enfin, dans models/marts, nous produisons une table analytique :
-- models/marts/mart_loss_ratio.sql
select
contract_id,
sum(claim_amount) as total_claims,
count(distinct claim_id) as nb_claims
from {{ ref('int_claims_enriched') }}
group by contract_id
Ce qui change fondamentalement n’est pas le SQL lui-même. C’est la structure.
Chaque modèle est indépendant. Chaque dépendance est explicite via ref(). DBT reconstruit automatiquement le graphe d’exécution.
Nous sommes passés d’un ensemble de requêtes dispersées à une architecture déclarative.
GitLab : la colonne vertébrale du projet
Dans le projet formation_dbt, le dépôt GitLab joue un rôle central.
Les transformations ne sont plus modifiées directement en production. Elles passent par :
- une branche de développement,
- une merge request,
- une revue de code,
- une validation automatique via CI.
La pipeline GitLab peut exécuter :
dbt deps
dbt seed
dbt run
dbt test
dbt docs generate
Chaque commit déclenche une validation complète du projet.
Si un test échoue — par exemple si un identifiant censé être unique ne l’est plus — la pipeline bloque. Le code ne peut pas être intégré.
Cela change profondément la culture de l’équipe. La transformation devient un artefact contrôlé.
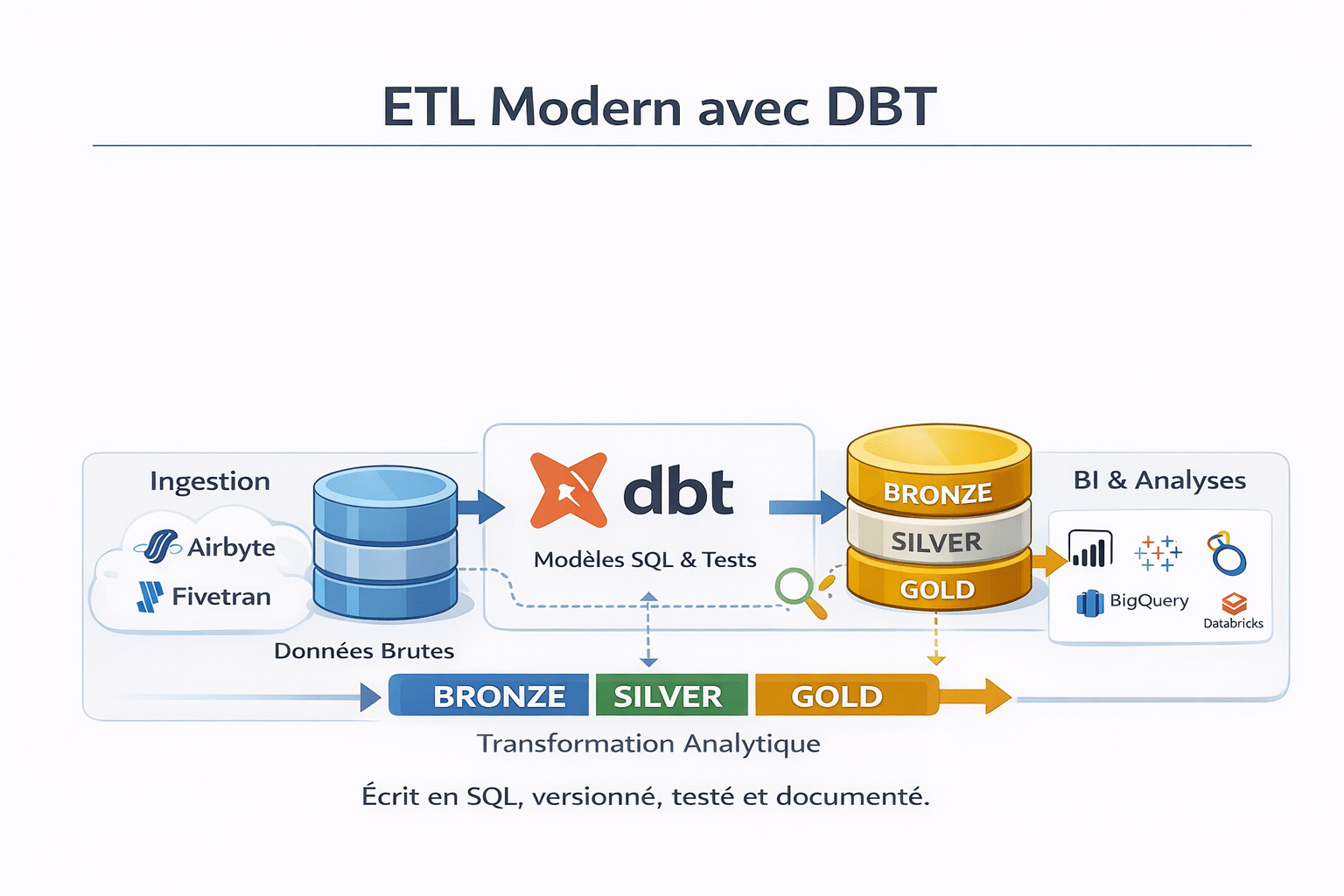
DuckDB : un moteur analytique léger pour industrialiser localement
Dans nos formations et POC, nous utilisons fréquemment DuckDB.
Pourquoi ?
Parce qu’il permet d’exécuter dbt localement avec un moteur SQL extrêmement performant, sans dépendre d’un warehouse cloud.
Cela permet :
- de tester les transformations rapidement,
- d’expérimenter les modèles,
- de former les équipes sans environnement complexe,
- de reproduire des pipelines analytiques complets en local.
Dans le projet formation_dbt, DuckDB permet de matérialiser les modèles, d’exécuter les tests et de générer la documentation sans dépendance externe lourde.
C’est un excellent compromis entre pédagogie et industrialisation.
La valeur stratégique du SQL
Un point essentiel dans nos accompagnements : SQL reste la compétence la plus stratégique dans la modern data stack.
Beaucoup d’organisations pensent que Python ou Spark remplaceront SQL. En réalité, la majorité des transformations analytiques restent relationnelles.
Les data warehouses modernes sont optimisés pour le SQL. DBT exploite directement cette puissance.
Le fait que DBT n’impose pas un DSL propriétaire, mais repose sur SQL, garantit :
- lisibilité,
- portabilité,
- performance native,
- appropriation rapide par les équipes.
Dans nos missions, nous constatons que le passage à dbt ne nécessite pas d’apprendre un nouveau langage. Il nécessite d’adopter une discipline d’ingénierie.
Les tests : passer de la confiance implicite à la validation explicite
Un autre changement majeur introduit par dbt est l’intégration native des tests.
Dans un fichier YAML, on peut déclarer :
models:
- name: mart_loss_ratio
columns:
- name: contract_id
tests:
- not_null
- unique
Ces tests deviennent exécutables via dbt test.
La qualité des données devient mesurable.
Au lieu de découvrir une incohérence dans un dashboard, on la détecte dès la phase d’intégration continue.
Dans des environnements sensibles — assurance, finance, secteur public — cette capacité à documenter et tester la transformation est déterminante.
La documentation et le lineage
L’un des aspects les plus puissants de dbt est la génération automatique de la documentation.
La commande dbt docs generate produit un site HTML interactif affichant :
- les modèles,
- leurs dépendances,
- les colonnes,
- les descriptions,
- les tests associés.
Dans le cadre d’un projet comme formation_dbt, cela permet aux équipes métiers de comprendre comment une métrique est construite.
La transformation devient transparente.
DBT et la gouvernance
DBT n’est pas qu’un outil technique. Il structure la gouvernance.
Dans un projet bien conçu :
- les sources sont déclarées explicitement,
- les transformations sont organisées par couche,
- les règles métier sont centralisées,
- les tests sont versionnés,
- les évolutions sont tracées via Git.
Cela facilite :
- les audits,
- les évolutions réglementaires,
- la maintenance,
- l’onboarding des nouveaux data engineers.
Ce que nous observons chez nos clients
Lorsque nous accompagnons une équipe vers dbt, plusieurs évolutions apparaissent rapidement.
- La dette technique diminue.
- Les discussions changent de nature. On parle moins de « pourquoi ça ne marche pas » et davantage de « comment améliorer le modèle ».
- Les équipes gagnent en autonomie.
- Les pipelines deviennent reproductibles.
La transformation analytique cesse d’être un assemblage de requêtes pour devenir une architecture structurée.
DBT n’est pas une mode
Il serait facile de présenter dbt comme un outil tendance.
En réalité, son succès repose sur des principes solides :
- versioning Git,
- séparation des responsabilités,
- exécution proche des données,
- tests automatisés,
- documentation intégrée.
Il ne remplace pas les outils d’ingestion.
Il ne remplace pas les moteurs analytiques.
Il structure la couche de transformation.
Et cette couche est stratégique.
Conclusion
Dans des projets comme formation_dbt, nous démontrons que dbt permet de transformer une suite de requêtes SQL en un véritable projet d’ingénierie analytique.
Il redonne au SQL sa place centrale.
Il apporte la rigueur du développement logiciel à la transformation.
Il rend l’ELT transparent, versionné et testable.
Chez Stat4decision, nous utilisons dbt :
- pour industrialiser des pipelines analytiques,
- pour structurer des modern data stacks,
- pour former des équipes data engineers,
- pour mettre en place des workflows GitLab robustes,
- pour concevoir des architectures ELT durables.
La transformation des données n’est plus un script.
C’est un projet.
Et aujourd’hui, dans la majorité des stacks modernes, ce projet passe par dbt.
Aller plus loin
DBT est disponible en version open source et peut être utilisé avec de nombreux moteurs analytiques (DuckDB, Snowflake, BigQuery, Redshift, Postgres, Databricks…).
Le repo GitLab associé au projet : https://gitlab.com/emjako/formation_dbt_maif
Pour découvrir le projet et sa documentation officielle :
- https://www.getdbt.com/
- Documentation technique open source : https://docs.getdbt.com/
Chez Stat4decision, nous accompagnons les organisations dans :
- la mise en place d’architectures ELT modernes,
- l’industrialisation de projets dbt avec GitLab CI/CD,
- la structuration bronze / silver / gold,
- l’intégration avec des warehouses cloud,
- la formation des équipes data engineers et analytics engineers.
Nous proposons également des formations dédiées à dbt et à la modern data stack, incluant :
- mise en œuvre d’un projet dbt de bout en bout,
- bonnes pratiques de structuration des modèles,
- tests, documentation et lineage,
- intégration Git et CI/CD,
- cas pratiques avec DuckDB et environnements cloud.
Pour en savoir plus sur nos formations et nos accompagnements :
https://www.stat4decision.com/fr/formations/
Partager cet article